前回まで で、AEイベントを収集するセンサーから信号を取り出し、Arduino で複数チャンネルのAD変換してイベントをとらえる事前検討 が
ArduinoIDE 長期ロギング用の実装を事前準備していたのですが、実際にロギングを開始してみるといくつもの新たな課題を確認しました。それらの課題はつぎのとおりです。
Flashへのイベントデータの記録ができない。 EEPROMなどのデータ回収でavrdude.exeを使うとリセットが発生する シリアルモニタを使うとON/OFFでリセットが発生する。 閾値を超えていないイベントが記録される。 ロギング用プログラムを起動した直後にイベントが記録される。 隣のチャンネルの信号の影響を受けているように見える。 これらの課題について、以下のように検討して、対処していきました。
Flashへのイベントデータの記録ができない。 できるだけ多くのイベントデータを記録できるようにEEPROMではなく、Flashに記録する方針でしたが、動作検証するとこのArduinoは、細工しないとFlashに記録できないことが判明しました。 次の件の課題もあり、Flashへの記録はあきらめて、EEPROMを目いっぱい活用することにしました。イベントデータは1ブロック8byteに圧縮する仕様としました。
EEPROMなどのデータ回収でavrdude.exeを使うとリセットが発生する avrdude.exeを使うには、一度リセットしなければならないことが判明しました。検討の結果、データ回収、などのすべての運用に必要な機能を、イベントロギングと並行で処理できるように実装することにしました。
シリアルモニタを使うとON/OFFでリセットが発生する。 シリアルモニタは、ON/OFFで、リセット信号を送信する仕様になっているようだ。シリアルモニタでデータ回収することも検討していたが、データを吸い上げる実装もロギングツール内に実装することにしました。
閾値を超えていないイベントが記録される。 これはいくつかバグや後述の項目の問題が関わっていました。
ロギング用プログラムを起動した直後にイベントが記録される。 リセット直後(ほぼ同時に)に閾値を越えていないイベントが複数回検出された。毎回検出されるわけではないが、記録量引きの少ないEEPROMを無駄に消費するので、これの対策を検討した。これが前段の件と関連して発生していた。どうもAD変換のレジスタにリセット直前の電位が残っていることがあるようだ。そこで、リセット直後の約1秒間はイベント情報をEEPROMに書き込まない仕様に変更しました。
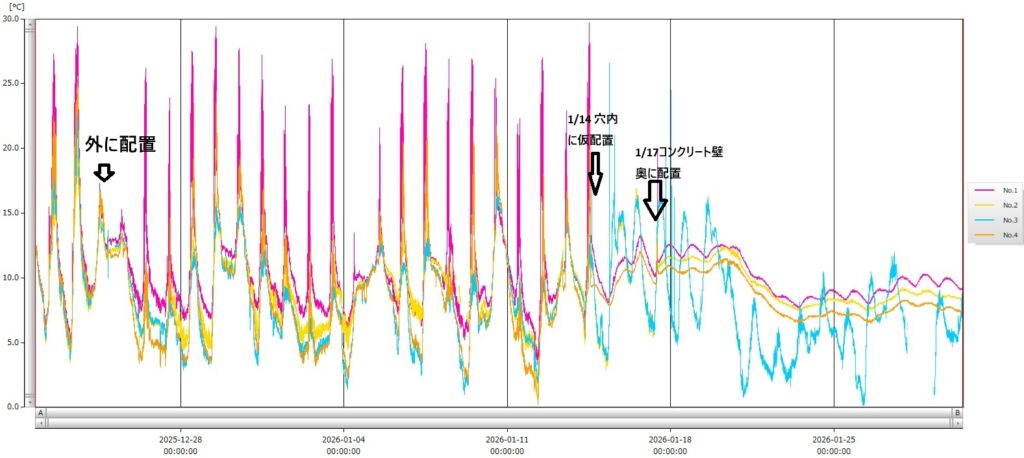
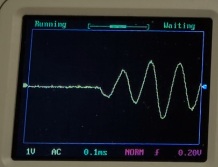
隣のチャンネルの信号の影響を受けているように見える。 隣のセンサーに影響が出ないように衝撃を与えた時に隣のチャンネルの信号の影響を受けているように見えた。当初、AD変換で直前のチャネルの電位の影響を受けて信号を拾っているのではないかと調整を試したが改善しなかった。 顧みると実験室で検証したときよりより多くの隣のチャンネルの影響を受けているようだった。試しに実験室内での計測したチャンネル切り替えで隣のチャンネルの影響を受けていなかったプログラムに戻して検証すると確かに、実験室の時より隣のチャンネルの影響が大きいことを確認した。この結果から、AD変換チャンネル切り替えの問題ではなく、物理的な信号ラインの クロストークが発生していると判断した。 フィールドへ配置する際に配線を束ねており、実験室に比べて電磁的クロストークが発生しやすい状況になったと推測されるそこで、信号ライン同士をできるだけ物理的に離すように調整した。 それでもある程度影響が残るので、可能な範囲で波形観測もできるように、リングバッファのほかに波形保存用のウインドウバッファを使う仕様に拡張しました。RAMではあるが、最後の2回については保存できるようにしました。
最終ロギング用 Arduinoスケッチ #include <EEPROM.h> 上記のArduinoスケッチのほかに、PC側のPowerShellツール(同期、EEPROMログ回収、EEPROMクリア、波形データ回収)を用意しています。
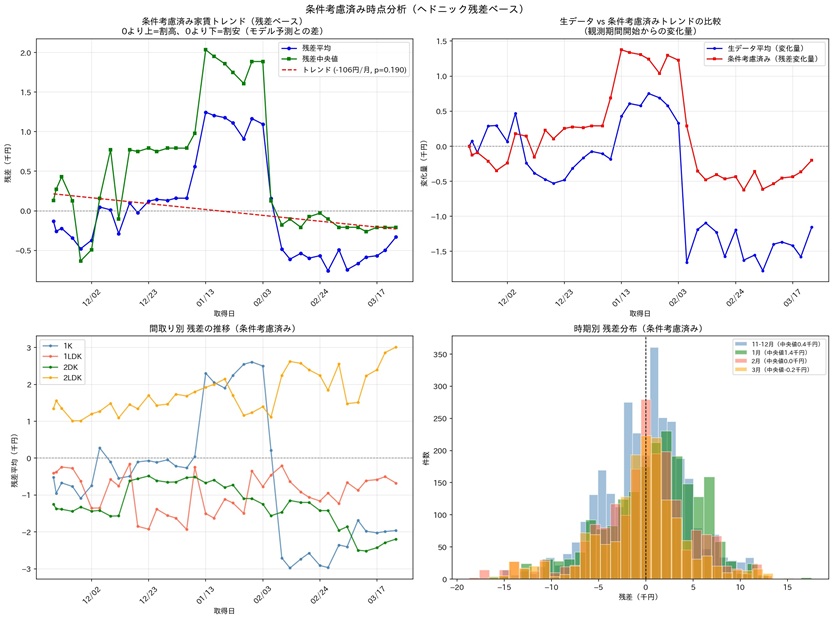
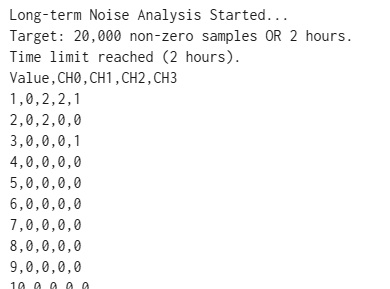
読みだした生データ(EEPROM) 02E7085F690004AA0300000009004B42 読みだしたデータ(波形分)(太文字は追記コメント) 1621795 ←1件目のイベント検出 millis ←2件目のイベント検出 millis ←ここから1件目の波形データ ←ここで閾値越え ←ここのへんから2件目の波形データ ←ここで閾値越え 本番運用開始直前の検証結果 [ EEPROM Data Analysis Report ] イベント情報は、上のログ解析結果のように確認できるようになりました。
当初の計画どおりとまでは言えませんが、これで、本番運用を開始できました。
関連記事 

 深刻
深刻