「データさえあればAIが分析してくれる」――そう思っていないだろうか。
筆者は最近、ある地域の賃貸物件データを使って家賃トレンドの分析を行い、その結果を別の記事 として公開した。「物価高騰は賃貸家賃に波及していない」「1月は割高、2月以降は割安」「追焚設備が家賃の最強予測変数」といった知見が得られた分析だ。
だがその裏側では、本格的な分析を始める前に、何時間もかけてデータセットの「確立」に苦労していた 。AIを使いながらも、AIだけでは絶対に見つけられない問題が次々と現れた。そしてその問題を見逃していたら、統計的には「有意」に見えるが事実とは異なる間違った結論が導き出されていた。
今回はその前処理の過程を正直に公開する。データサイエンスの「格好いい部分」の前にある、泥臭くて地味だが最も重要な工程の話だ。
そもそも「前処理」とは何か データ分析の工程は大まかに以下の流れになる。
データ収集 (スクレイピング等)前処理・データセット確立 ← ここが今回のテーマ探索的分析(EDA) モデル構築・検定 結果の解釈・レポート 前処理とは「生データを分析できる状態に整える」作業のことだ。具体的には欠損値の処理、型変換、外れ値の除去、重複の排除などが含まれる。
教科書的にはシンプルに聞こえる。しかし現実のデータは教科書とは全く違う顔を持っている。
罠①「文字列で格納された数値」――AIは気づかない スクレイピングで取得した家賃データの形式はこうだった。
rent: "4.1万円"
admin: "4500円"
sikik: "1.5万円"
数値のように見えるが、Pythonの内部では全て文字列(string)型 として格納されている。そのままモデルに渡せばエラーになるか、全件NaN(欠損値)になる。
「4.1万円」→ 41,000円への変換は一見単純だが、実際のデータには「-」(敷金なし)「応相談」「無料」など例外が無数に存在した。変換ロジックを書いても、次々と変換失敗するパターンが出てくる。
AIへの指示で自動変換を試みたところ、AIは「変換成功」と報告した。しかし実際には変換失敗した行が大量にNaN化していた。 AIは処理を実行したことは正確に報告するが、結果の妥当性を自ら検証する習慣を持たない。確認コードを別途書いて人間が検証する必要があった。
データ解析と問題発見 罠②「DateTime型がモデルに混入する」――エラーなく通ってしまう データには取得日(today)と取得タイムスタンプ(source_timestamp)という時系列の列があった。これらは当然、説明変数から除外すべき列だ。
ところがStandardScaler(標準化処理)にこれらをそのまま渡したとき、エラーは出なかった 。Pythonは自動的にdatetime型を数値に変換して処理を続行したのだ。
結果として「取得日が新しいほど家賃が高い/低い」という意味のない相関がモデルに混入し、係数が歪んでいた。エラーが出ないため発見が遅れた。AIもこの異常を指摘しなかった。
「エラーなく動く」≠「正しく動いている」。これが前処理の恐ろしさだ。
罠③「ユニークキーの誤設定」――最も危険な罠 今回のデータは「同一物件を複数の取得日にわたってスクレイピングした」時系列パネルデータだ。分析するには「1物件 = 1レコード」に集約する必要がある。そのためにはまず「同一物件を識別するユニークキー」を正しく定義しなければならない。
これが最も深刻な罠だった。3回の定義変更を経て、ようやく正しい答えにたどり着いた。
v1: 物件名(title)単体をキーとして使う 最初は「物件名が同じなら同一物件」と考えた。しかしすぐに問題が発覚した。
「Tiare」「Bonheur」のようなマンション名は、同一棟の複数の部屋(1階・2階・異なる間取り)が同じ名前で掲載されている。title単体でキーを引くと、本来は別レコードであるべき複数の部屋が1件に誤集約 される。
v2: SUUMO物件コードをキーとして使う 次に「サイトが付与している物件コード(suumo_code)が最も信頼できるはず」と考えた。しかしここに大きな落とし穴があった。
大手賃貸サイトは同一物件の掲載コードを定期的に更新する仕様だった。
これを確認したときのデータはこうだった。
suumo_code 観測期間 取得率 100493030331 2026-03-10〜03-10 1日のみ 100493042285 2026-03-13〜03-20 2日
これは実際には同一物件なのに、コード更新によって2件に分裂している。レオパレス系の物件では取得率の中央値がわずか26.5% ――つまり38時点中約10回しか同じコードで観測されていない。同一物件が平均4コードに分裂していた計算になる。
この誤集約版でモデルを動かしたときのR²(決定係数)は0.836 。見かけ上は非常に高精度なモデルに見えた。しかし実態は水増しされたサンプル数による見せかけの精度だった。
v3(最終): Union-Findアルゴリズムで連結する 最終的な解決策は、Union-Find(素集合データ構造) というアルゴリズムを使った連結だ。
「物件名・不動産会社コード・階数・間取り・家賃が同一で、旧コードの最終観測日と新コードの初回観測日のギャップが7日以内」という条件を満たすものを同一物件として連結する。
連結前: 1,522件
連結後: 1,371件(151件を連結)
募集期間の中央値: 4日(異常)→ 52日(現実的)
募集期間の中央値が4日から52日に変化した時点で「ようやく正しい集約ができた」と確認できた。入居が決まるまでの期間として4日は明らかに異常で、52日は現実的な値だ。
そして正しい集約後のモデルのR²は0.750 。v2の0.836より低い。これが正しい精度だ。高いR²が必ずしも「良いモデル」を意味しない典型例だ。
罠④「多重共線性」――変数を増やすほど精度が下がる逆転現象 ユニークキーが確立した後、次の罠が待っていた。
間取り(1K・2LDKなど)と専有面積(㎡)は、直感的には別の情報のように見える。しかし統計的にはほぼ同じ情報を異なる形で表している に過ぎない。
両方を同時にモデルに投入すると、VIF(分散拡大係数)が以下のようになった。
変数 VIF 判定 madori_1K(間取り) 69.8 madori_2LDK 57.2 menseki(面積) 22.5
VIF>10は多重共線性ありの目安とされる。間取りダミー変数を全て除外して面積のみにしたところ、VIFは全変数で10以下に収まり、調整済みR²も改善した。
「変数を増やす = 精度が上がる」という思い込みは危険だ。 不適切な変数の追加は、むしろモデルを壊す。
「見かけの下落トレンド」が前処理の重要性を証明した これら全ての前処理を経て初めて、時系列分析が意味を持つようになった。
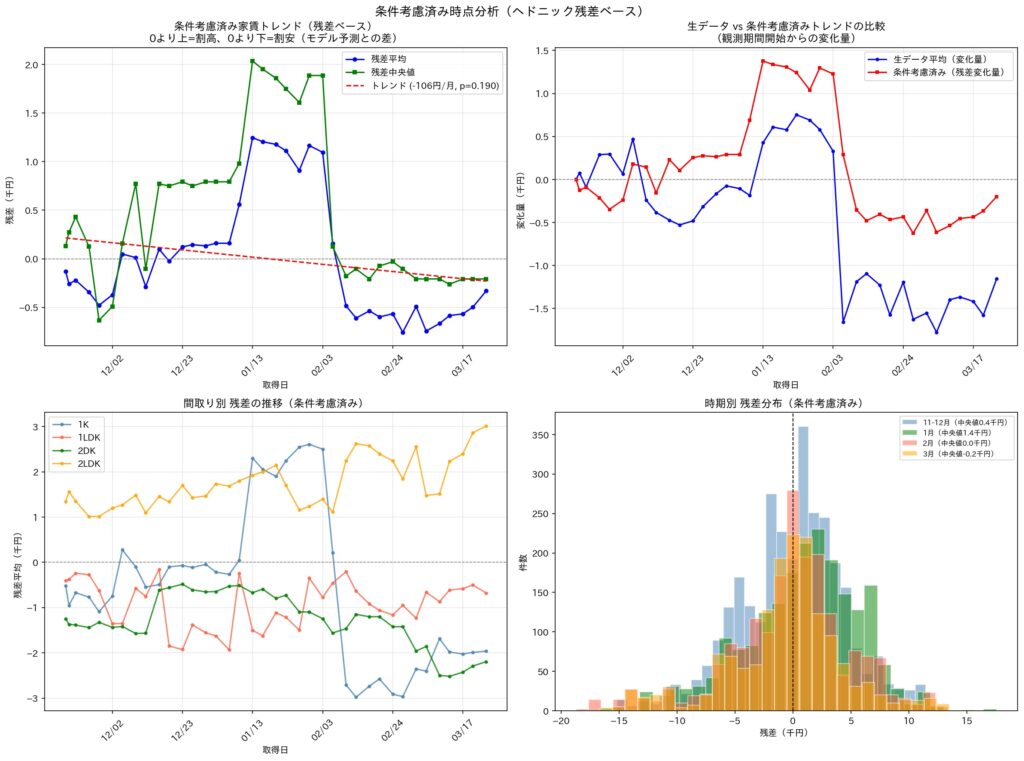
生データの平均家賃をそのまま時系列でプロットすると、月▲380円という明確な下落トレンドが見えた(p<0.001)。もし前処理が不十分なままここで分析を終えていれば、「この地域の家賃は有意に下落している」と結論づけていただろう。
しかし物件条件(面積・築年数・設備など)を除去したヘドニック残差で同じ分析をすると、トレンドは月▲106円でp値=0.190——統計的に有意でない 。
「下落トレンド」の正体は、安価な物件の大量新規掲載によるミックス効果だった。前処理が正しくなければ、この区別は絶対にできなかった。
なぜAIだけでは限界があるのか 今回の分析でAIは非常に重要な役割を果たした。Pythonコードの生成、統計的な解釈、可視化スクリプトの作成——これらはAIなしでは数倍の時間がかかっていた。
しかし以下の判断は、人間の「データへの疑い」なしには気づけなかった。
問題 なぜAIが見落とすか 文字列型の数値変換失敗 「処理した」事実を報告するが、結果の妥当性を自ら検証しない DateTime型のモデル混入 エラーが出ないため異常として認識されない suumo_codeの定期更新仕様 ドメイン知識(サイトの仕様)を持っていない 募集期間「中央値4日」の異常 「4日は短すぎる」という現実感覚がない R²=0.836の見かけ上の高精度 高いR²を「良い結果」として肯定してしまう傾向がある
AIは与えられた指示を忠実に実行する。しかし「この結果はおかしい」「この集約方法は現実と合っているか」というドメイン知識に基づいた懐疑心 は、人間が持ち込まなければならない。
データサイエンスは「AIに任せれば終わり」ではない。むしろAIを使えば使うほど、人間側の「問いを立てる力」と「結果を疑う目」が重要になる。
まとめ:前処理は「分析の9割」である 今回の分析で前処理に費やした時間は、モデル構築や解釈の時間をはるかに超えていた。そしてその前処理の品質が、最終的な結論の正否を決定的に左右した。
前処理の重要なチェックポイントをまとめる。
型変換の結果を必ず検証する (変換後のNaN率、値の範囲を確認)除外すべき列を明示的にリストアップする (ID列・日付列・生テキスト)集約結果が現実と整合するか確認する (「募集期間4日」は現実的か?)ユニークキーの定義を慎重に行う (データソースの仕様を調査する)VIFで多重共線性を確認する (変数を増やす前に必ず確認)高いR²を盲信しない (集約バグや過学習の可能性を疑う)「正しいデータセット」なしに「正しい結論」はあり得ない。前処理はデータサイエンスの花形ではないかもしれない。しかし、それが全ての土台だ。
データ分析のご相談はhoscmへ 「自社のデータを分析したいが、どこから手をつければいいかわからない」「AIを使ってみたが正しい結果が出ているか不安」——そんなご相談を承っています。
データの収集設計から前処理・モデル構築・結果の解釈まで、一貫してサポートします。まずはお気軽にご相談ください。
hoscm サービスサイト




 深刻
深刻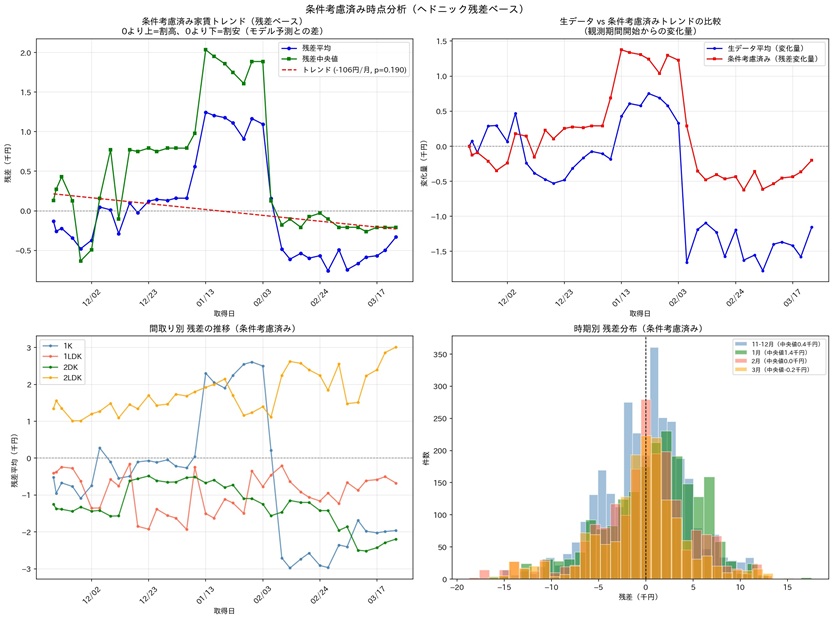




 追記:2026年4月更新──ダウングレード不可、YouTube側変更の隣
追記:2026年4月更新──ダウングレード不可、YouTube側変更の隣