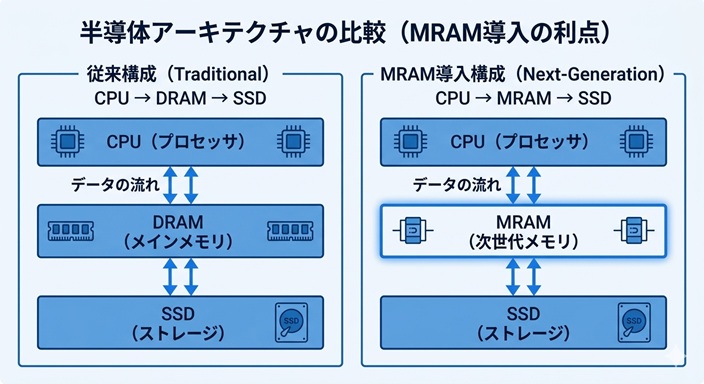
第5話SSDは本当に速いのか──見落とされがちな「速度の盲点」 ではSSDが常に高速とは限らず、状況によっては速度が低下することがある点を取り上げた。多くの場合、その現象は「SSDは万能ではない」という理解で片付けられてしまう。しかし、その裏側にはもう一つの事情がある。そのためSSDの内部では、寿命をできるだけ長く保つためのさまざまな制御が行われている。前回触れた速度の変化も、実はその **「寿命を守る仕組み」**と深く関係している。Flashメモリの書き込み寿命という制約 を知る必要がある。そこで今回は、SSDの根本的な特徴とも言える Flashメモリの書き込み寿命 について見ていく。
SSDはなぜ劣化するのか。どの程度の寿命があるのか。そして、それは実際の運用にどのような影響を与えるのか。速度の話のさらに奥にある、SSDの「もう一つの現実」を整理してみよう。
1 フラッシュメモリはなぜ劣化するのか 第5話では、SSDが時間とともに遅く感じられる理由を説明した。その背景には、ガベージコレクションやウェアレベリングなど、内部管理処理の増加がある。フラッシュメモリそのものの性質 を知る必要がある。書き込みには寿命がある。 絶縁膜を強い電圧で通過させる という動作で行われる。
この処理は元の状態に完全に戻るものではない。書き込みと消去を繰り返すたびに、絶縁膜は少しずつ劣化していく。つまりフラッシュメモリは、使えば減る寿命 を最初から持っているストレージである。
この寿命は、一般に P/E回数(Program / Erase cycle) として示される。セルがどれくらいの回数、書き込みと消去を繰り返せるかの目安だ。この耐久性の違い にも関係している。SSDはこの制限を前提に設計されている という点である。フラッシュメモリの寿命は避けられない。だからこそSSDは、書き込みを分散し、劣化を管理しながら動作する。
第5話で見た「速度の変化」は、実はこの寿命管理の仕組みの一部でもある。そしてこの仕組みを理解すると、SSDの使い方について、もう一つの視点が見えてくる。
それが、「速く使うこと」と「長く使うこと」は、実は同じ方向にある という考え方である。
2 書き込み回数という制約 フラッシュメモリの寿命は、しばしば「書き込み回数」で語られる。
SLC:約10万回 MLC:約数千回 TLC:約1000回前後 といった数字を見たことがある人も多いだろう。しかし、この数字は「その回数で壊れる」という意味ではない。実際には、同じ回数を書き込んでも、すべてのセルが同じように劣化するわけではない。
あるセルは早く劣化し、別のセルはずっと安定した状態を保つ。
NANDフラッシュを構成する個々のセルのレベルで見ると 、劣化は書き込み回数の増加とともに進む摩耗型の変化 である。
しかし、SSDやUSBメモリといった装置全体のレベルで見ると 、この劣化は単純な直線として現れるわけではない。実際には、セルごとの製造ばらつきや使用条件の違いによって、劣化の進み方に差が生じる。そのためストレージ全体として観察すると、寿命の変化は一様な摩耗曲線ではなく、セルごとのばらつきを背景にした統計的な現象として現れる 。
この性質があるため、SSDの内部では
書き込み位置を分散する 劣化したセルを避ける エラー訂正を強化する といった管理処理が行われている。
言い換えると、SSDは
SSDは「壊れない装置」として設計されているわけではない。装置全体として安定した動作を保つよう設計されたストレージ である。
こうして、セルごとの状態のばらつきが少しずつ大きくなってくると、内部の管理処理が増え始める状態 になる。
このとき現れやすいのが、速度や応答性の変化 である。
SSDの内部では、管理処理 が行われている。
セル単位では、まだ寿命に達していないものがほとんどであり、故障した状態ではない 。
しかし、セルの状態のばらつきが増えると、内部処理の回数や負荷 が増えていく。
その結果として現れるのが、「SSDが少し遅くなった」ように感じる現象 なのである。
3 SLC / MLC / TLC / QLC の本当の違い 前節で触れた通り、SSDの速度や耐久性は、単に「高速か低速か」では語れない。セルごとの物理特性や構造、さらに制御の工夫によって、同じSSDでも使い方次第で性能や寿命は大きく変化するのだ。ここでは、代表的なフラッシュメモリの種類である SLC、MLC、TLC、QLC を取り上げ、それぞれの特徴と設計上の意図を整理してみよう。
セル種類 速度 耐久性 容量効率 技術的工夫・実現方法 SLC ◎ ◎ × 1セルに1ビットのみ記録。セル状態は2値(0/1)のみで安定性高く、書き換え耐性も高い MLC △ △ ◎ 1セルに2ビット記録。電圧を4段階に分けてセル状態を管理。高速性・耐久性はSLCより低下 TLC △~× △~× ◎◎ 1セルに3ビット記録。電圧を8段階に分け、多段階制御と誤り訂正(ECC)で信頼性確保 QLC × × ◎◎◎ 1セルに4ビット記録。電圧16段階管理。ECCや書き込み分散制御(ウェアレベリング)必須で高速性維持
技術的ポイント補足 電圧分割で多ビット記録 MLC:4段階電圧で2ビット/セル TLC:8段階電圧で3ビット/セル QLC:16段階電圧で4ビット/セル 誤り訂正と分散制御 ECC(Error Correction Code)やウェアレベリングを用いて、書き込み耐性の低い多ビットセルでも安定動作を実現 トレードオフの理解 SLC:速度・耐久優先 → 容量効率低 QLC:容量・コスト優先 → 速度・耐久性低 技術的視点:セルサイズと積層構造 SLC~QLCの違いは、単に「1セルに記録するビット数」だけではない。セルの物理サイズの縮小 や**積層構造(3D NAND)**といった技術も組み合わされている。
記録密度を高めるための方法は大きく二つある。
セルを小さくして平面方向の密度を上げる セルを垂直方向に積み上げる それぞれが異なる技術的課題を持っている。
セル密度(セルの微細化) セルを小さくすると、同じ面積により多くのセルを配置できるため、記録密度は向上する。
しかしセルが小さくなると、蓄えられる電荷量も減る。
耐久性が低下しやすい 書き込み制御が難しくなる つまり、セルの微細化は記録密度を高める一方で、耐久性と書き込み制御の余裕を小さくする方向に働く。
積層(3D NAND) もう一つの方法が、セルを垂直方向に積み重ねる3D NAND構造 である。
平面上でセルをこれ以上小さくするのが難しくなったため、
積層構造では、セルサイズを極端に小さくせずに記録密度を高められる。
配線やアクセス経路が長くなる 読み書き制御が複雑になる セル管理のための制御処理が増える その結果、SSD内部ではより高度な管理アルゴリズム が必要になる。
ここのようにフラッシュメモリでは、
・1セルの多値化(SLC→QLC)
といった技術を組み合わせて記録密度を高めている。
しかし物理的には、高速性・耐久性・記録密度・コスト をすべて同時に最大化することはできない。
そのため実際の製品では、どの性能を優先し、どこで折り合いをつけるか という設計判断が必要になる。
SSDの仕様やグレードの違いは、
4 SSDはどうやって寿命を延ばしているのか 「壊れ方」を管理するコントローラ 半導体メモリの容量は、長い間2のn乗 という形で増えてきた。
64KB、128KB、256KB、512KB……。
この増え方は偶然ではない。メモリはアドレス信号によってセルを選択する構造になっており、アドレス線が1本増えるごとに、アクセスできるセル数は 2倍 になる。さらにセルは行列のマトリクス構造 で配置されるため、この2倍単位の増え方は、半導体メモリの設計と自然に対応している。これは主に SRAM や DRAM の世界の話 である。
この世界では、すべてのメモリセルが正常に動作し続ける ことを前提にしても均質なセルの集合 として扱うことができた。
一方、ストレージの世界では昔から別の表現が使われていた。「HDDの容量は羊羹である」 という比喩がある。 羊羹を包丁で切るように、ディスクの容量は好きな長さで切り分けて使える 。
20GB
といったように、必ずしも 2のn乗 にはなっていない。
これはHDDが「2^nの容量になる必然性がない」記録領域を持つ装置 だからである。
一方、SSDやUSBメモリの内部で使われているNANDフラッシュメモリ は、半導体メモリである。
そのためフラッシュメモリチップ単体は、
8GB
といったように、2のn乗の容量 で製造されている。
しかしSSDという製品になると、容量は必ずしもその形にはならない。
480GB
といったように、2のn乗から少し外れた容量 が普通に存在する。
メモ: さらには、USBメモリ自体も各個体のUSBメモリのサイズをエクスプローラーなどで確認すると容量が微妙に異なっていることを確認できる。 これはSSDがセルの故障を許容する設計 を採用しているためである。フラッシュメモリのセルは、書き込みを繰り返すことで必ず劣化する。そのためSSDでは、すべてのセルが同じ寿命で最後まで使えることを前提にするのではなく、一部のセルが故障しても装置としては動き続ける という考え方で設計されている。予備領域(オーバープロビジョニング) が用意される。また製造段階でも、不良セルの配置などによって利用可能な領域はわずかに変わる。
その結果、フラッシュメモリチップ自体は2のn乗であっても、SSD製品としての容量は必ずしも2のn乗にはならない。
言い換えれば、半導体メモリでありながら羊羹のような容量管理 が行われるのである。
そして、このような使い方で関係してくる、もう一つ重要な要素が存在する。それが、コントローラによる寿命管理 である。 SSDは壊れない装置 として設計されているのではない。壊れ方を管理する装置 として設計されているのである。
コントローラが行っている「寿命管理」 セルごとに寿命にはばらつきがあり、使われ方によって劣化の進み方も変わる。もし同じ場所にばかり書き込みが集中すれば、そのセルだけが早く寿命を迎えてしまう。そこでSSDのコントローラは、書き込みを装置全体に分散させるように動作している。たとえば、同じファイルを書き換えているように見えても、内部では毎回別のセル に書き込まれていることが多い。ウェアレベリング(Wear Leveling:摩耗平準化技術) と呼ぶ。
さらにSSDは、壊れ始めたセルを検出して使用を避けたり、エラー訂正によって読み出しを補助したりといった処理も行っている。
つまりSSDの内部では、
書き込みを分散する 劣化したセルを避ける エラー訂正で読み出しを補助する といった複数の仕組みが組み合わさり、装置全体の寿命を延ばすように設計されている。言い換えればSSDは、
セルの寿命を延ばしているというよりも、
なのである。
ウェアレベリング(Wear Leveling:摩耗平準化)の話は、既に第5話でしているので、スペック的な話はそれを参照してほしい。 SSDを長く、そして速く使うにはどうすればよいのでしょうか。
5 SSDを長く速く使える人の使い方 SSDの寿命を決めるのは 書き込み です。
NANDフラッシュメモリには書き込みと消去を繰り返せる回数(P/Eサイクル)に上限があります。つまりSSDにとって重要なのは
保存しているデータ量 どれだけ書き込みが発生しているか です。
ここまでは第5話で説明しました。
しかし実際のSSDでは、単純に「ユーザーが書き込んだ量」だけで寿命が決まるわけではありません。SSD内部では、書き込みに伴っていくつかの処理が発生するためです。
その代表が ガーベジコレクション(Garbage Collection) です。
SSDでは既存データを直接上書きすることができません。
新しい場所に更新データを書き込む 古いデータは「無効」として扱う 後でまとめてブロック単位で消去する この「まとめて整理して消す処理」がガーベジコレクションです。
例えば、あるブロックに次のようなデータがあったとします。
[A][B][C][D] ここで A が更新された場合、SSDはAと同じ場所を上書きするのではなく、
[A’] この時点で元のブロックは
[invalid][B][C][D] のような状態になります。
ブロックには有効データが残っているため、すぐには消去できません。
B C D を別の場所へコピーし、その後でブロック全体を消去します。
このとき内部では
といった 追加の書き込み が発生します。
つまり、ユーザーが行った書き込みは
A → A' の1回だけですが、SSD内部では
B といったコピー書き込みが追加で発生します。
このように、ユーザーが書き込んだ量よりも実際の書き込み量が増えてしまう現象をWrite Amplification(書き込み増幅) と呼びます。
そして、この現象はSSDの使い方によって大きく変わります。
特に影響が大きいのは
頻繁な更新処理 小さな書き込みの繰り返し 同じデータ領域の繰り返し更新 といったパターンです。
これらの操作では、SSD内部でガーベジコレクションが頻繁に発生し、結果として実際の書き込み量が増えていきます。ここで重要なのは、SSDは内部でウェアレベリングによって書き込みを分散させようとする、という点です。つまり、ユーザーが「同じ場所を更新している」つもりでも、実際にはSSD内部では別のセルへ書き込みが分散されます。しかしその結果として、ガーベジコレクションによるコピー処理が増え、最終的には NANDへの書き込み総量が増える という形で負荷が現れます。
つまり、SSDに負荷を与えるのは「同じセルへの書き込み」そのものではなく
頻繁な更新処理そのもの です。
SSDを長く使うという観点では、
(不必要に)更新を繰り返さない 小さな書き込みを大量に発生させない といった使い方が、結果としてSSD内部の書き込み量を抑えることにつながります。
なお、ガーベジコレクションの基本的な動作については、
(GCの基本動作を説明した動画)
VIDEO
この動画はSSDの内部処理を簡略化した説明ですが、「更新 → 無効データ → まとめて整理」という流れは実際の動作に近いものです。
SSDは単なる「速い記憶装置」ではなく、内部でかなり複雑なデータ整理を行いながら動作しています。
そのため、SSDの寿命や性能を考える上で重要なのは単純な容量や空き領域ではなく、
どのような書き込みパターンが発生しているか
なのです。
※参考動画 https://www.youtube.com/watch?v=E8xr087Ka0c
6 壊れたUSBメモリの中で起きていたこと ここまで見てきたように、フラッシュメモリの寿命は「突然の故障」として訪れるものではない。多くの場合は、動作の変化として先に現れる 。
つまり、「速いまま使える時間」を長くするということは、単に快適さの問題ではない。それは、ストレージの寿命を先送りする使い方 でもある。
そしてこの話は、決してSSDだけの話ではない。実際に、長く使っていたUSBメモリのひとつが、ある日から書き込みが極端に遅くなり 、やがて正常に使えなくなった。
故障と言えば故障なのだが、その挙動を見ていると、単なる突然死というより、内部のフラッシュが限界に近づいた結果 のようにも見える。実際に分解して調べてみた記録 を紹介したい。
関連記事