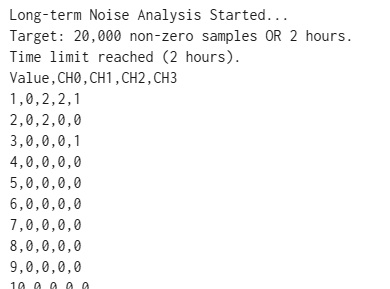
前回までで、センサーから信号をとりだすアナログ部分の仮構築 が完了しました。ここからは、取り出したAE信号をAD変換してロギングする部分を構築していきます。アナログ部製作編 )の採用するシステム構成の方針により、ロギングシステムの中核につぎのパーツを採用しました。
AD変換&ロギング部 [107385]Arduino Uno Rev3
事前検討方針 ドキュメントレベルの調査結果から、次の課題があることを確認しました。
Arduino IDE に必要なスペックを確認しておく。Windows 10以降のPCならほぼ大丈夫。Arduino 公式ソフトウェアページ
動作確認 PCにArduinoを繋ぎ、デバイスマネージャーの「ポート(COMとLPT)」に「Arduino Uno」が表示されるか確認する。
USBを挿す前は Port のさきに COM3などが見えていましたが、 USBをさすとPortがグレーアウトされました。
最初の動作確認 出荷時は、次のサンプルが動いているようです。サンプルを開く :「Blink」 「→(書き込み)」ボタン を押すと、コードを書き込んで点滅間隔がかわる。
Arduino Unoの動作状況確認 Arduino Unoは基本1方向らしい、吸出しなどはavrdude コマンドらしい。
パラメータを確認 > .\avrdude.exe -? ■flash(プログラム領域)の吸い上げ の試行
.\avrdude.exe "-CC:\Users\<ユーザ名> \AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17/etc/avrdude.conf" -v -p atmega328p -c arduino "-PCOM4" -b115200 -U flash:r:backup.hex:i <ユーザ名> \AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17/etc/avrdude.conf"上の実行の結果、ファイルが実行パスに出力されていることを確認しました。
> .\avrdude.exe "-CC:\Users\<ユーザ名> <ユーザ名> eepromのデータを読み出せました。ファイルサイズは3kbです。ですが、中身はFlashメモリの冒頭部分と同じようでした。 確認のため、 eeprom_clearというサンプルをアップロードして確認してみます。→結果、再度読み込んだファイルの中身は、変わりませんでした。 上のEEPROMの読み出しは機能していないようです。失敗しているよう。
サンプルに、eeprom_clearや eeprom_readがあるのでこれを使ってみます。eeprom_readをアップロードして確認してみます。右上のシリアルモニタとシリアルプロッタを使って、確認すると。EEPROMの1kb分が0で帰ってきました。
基本的な動きが確認できたので、ここでの検証課題のUSB挿抜でのリセット発生状況の確認と回避確認です。「 Arduino IDE(PC側)のシリアルモニタを開く操作をすると、Arduinoボード本体に自動的にリセットがかかる 」 らしい、USB挿抜以外にもチェックするべき観点が増えた。
さて、要因は1つ増えたが、対策は増えていないので、方針は変えずに先に進めよう。MCUSR (MCU Status Register) レジスタ」でできるらしい。
MCUSRレジスタのビットマップ解説 本番向け実装も考慮して、MCUSRレジスタ も含めてデータ構造設計をします。方針は、あらかじめデータ保存領域を00クリアしておきます。データ登録はブロック単位でおこない、更新は追記のみで上書きはしないものとします。MCUSRレジスタ
LED点滅による通知仕様
できるだけ長期間のロギングをしたいために、無駄なデータ領域を消費しないようにする。
Unix Timeは4バイト(32bit)すべてを格納。
バイト 0 1 2 3 4 5 6 7 備考 01 (Reset) 01MCUSR <— millis(4B) —> 0000最もシンプルな構成 02 (Sync) 02<— Unix Time(4B) —> <— millis(4Bの一部) —> ※後述 1x (Data) 1x00<— millis(4B) —> <— AD値(2B) —>
1. EEPROM走査関数: 起動時に先頭から8バイトずつ読み、01の数を数えつつ、最初の00を見つける。
2. リセット記録: setup()の最初で01レコード(MCUSR付き)を追記。
3. LED点滅関数: loop()内でmillis()を監視し、カウントされた回数分だけ点滅(delayを使わない)。
4. PC同期受信: シリアルで 0x02 を受信したら、続く4バイトをUnix Timeとして処理。
※補足:3ヶ月ロギングで1KBのEEPROM(128回分)が溢れるのが心配な場合は、追記時に「これ以上書かない」というガードも入れる。
1.書き込み位置特定: 8バイトすべてが 0x00(完全な未使用領域)であることを条件に、追記位置を決定します。 ここまで作業が進んだところで、EEPROMの読み込み問題に気が付いたので先に書いた対策を実施しました。詳しくはこちらを参照してください→「Arduino Uno 事前検証過程(その3の1)でのEEPROM読み出し問題の回避策 」
本体実装 (Arduinoスケッチ ResetDetector.ino) まず、リセットと同期の実装を入れた実験版です。
/* 同期実装(PowerShell sync.ps1) 同期処理を行うのに使用します。 ファイルを右クリックして、「PowerShellで実行」をくちっくして使用します
$ErrorActionPreference = "Stop" # 全てのエラーを「中断(catchに飛ばす)」対象にする 実験結果 同期処理の実行結果は次の通り
送信成功: UnixTime = 1767166738 (CheckSum: 0xA2) リセットの発生状況の検証を実施しました。 USBの挿抜では、リセットは発生していないようです。
検証用コード (PowerShell: reset.ps1)
# --- 設定 --- 実行結果は次の通り。 このリセット後は、LEDの点滅は3回になりました。 設計通りの挙動です。 このあと、もう一度同期して一旦実験完了です。
Port COM4 Opened. それでは、EEPROMにロギングした結果を吸い出して検証してみましょう。
:100000000100000000000000023AD25469D50F0040 ほぼ想定の結果が得られました。比較的うまくいっているようです。これからわかることは、01 (reset)の次はすべて00で、MCUSR レジスタから得られた情報はなさそう。
参考サイト: avrdude の使い方 (電子工作の実験室) Arduinoのプログラムを吸い出す方法 (Lang-ship)
関連記事