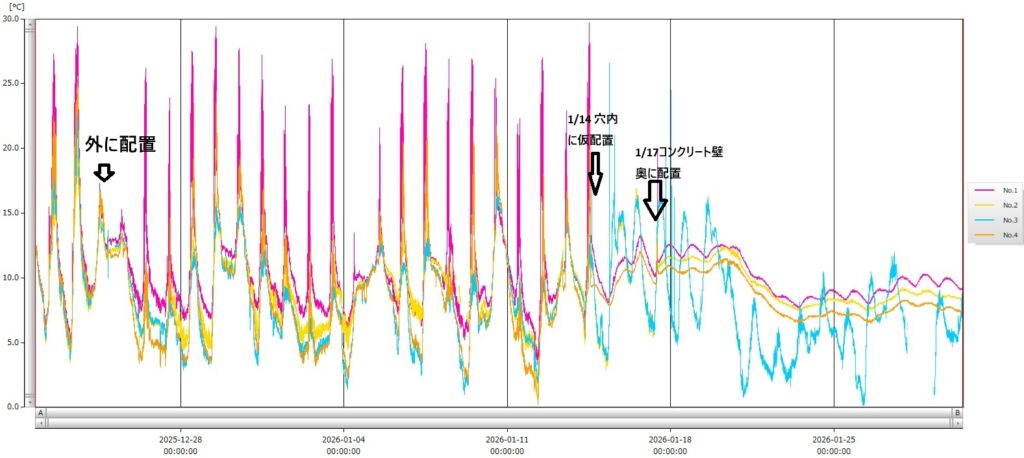
ついにAE がとられた、コンクリート悲鳴 を。それは4月3日だったようだ。EEPROMのデータ保存の限界をも超える回数がこの日に集中して発生した。
そのデータは次の通り
[ EEPROM Data Analysis Report ] このように、4月2日以前は、ほとんどそのようなことがなかったが、4月3日に異常なAEの発生が頻発している。最初は4月3日のAM9:00ころから、ここで何があったのか気象情報を確認した。これまでの画像データ解析で気になった、雨が関連するのかを確認したが、この時間帯は、晴れで、雨も降っていないし、風も2m/s程度でそれほど吹いていなかった。
そこで、これが原因ではないかと言うことで、仮説と事例や関連情報を確認した。いかは、その結果をGEMINIが、まとめたものである。
コンクリートが「膨らんで」割れる?湿度差が生む『反りの拘束』とひび割れのメカニズムを徹底解説 コンクリート構造物の表面に、身に覚えのないひび割れや、わずかな「膨らみ」を見つけたことはありませんか?一般的にコンクリートは「乾燥して縮む(乾燥収縮)」ことで割れると思われがちですが、実はその裏側にある「湿度の不均衡」が真の原因であるケースが少なくありません。 特に、片面が土に接し、もう片面が外気にさらされているような環境では、コンクリート内部で巨大なエネルギーが衝突しています。本記事では、専門家も注目する「反りの拘束」によるひび割れメカニズムを、図解とともに分かりやすく解説します。
1. コンクリートは「生き物」のように動いている? 1-1. コンクリートの体積変化を引き起こす4つの要因 コンクリートは一度固まれば岩のように変化しないと思われがちですが、実は環境の変化に応じて常に微細な伸縮を繰り返しています。
温度変化: 熱くなれば膨らみ、冷えれば縮みます。湿度変化: 水分を吸えばわずかに膨張し、乾けば収縮します。化学反応: 内部の成分が反応して異常膨張を起こすことがあります(アルカリ骨材反応など)。外力: 土圧や上部構造の重みによる物理的な圧力。1-2. なぜ「湿度」が重要なのか コンクリートの内部には、目に見えないほど微細な「空隙(くうげき)」が無数に存在します。この隙間に含まれる水分の量(含水率)が変わることで、コンクリート組織を構成する粒子間の距離が変化し、それが全体の「体積変化」として現れるのです。
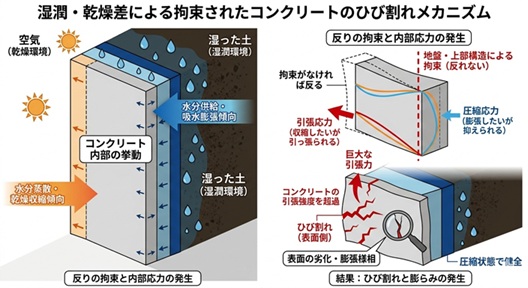
2. 片面が土、片面が空気――この「不均衡」が引き金になる 2-1. 裏面(土側)で起きている「吸水膨張」 地下室の壁や擁壁、ベタ基礎など、片面が常に湿った土に接している場合、その面は常に水分を供給され続けます。これにより、コンクリートの裏側は「膨張」しようとする、あるいは少なくとも「収縮しない」状態が維持されます。
2-2. 表面(空気側)で起きている「乾燥収縮」 一方で、太陽光や風にさらされている表面は、水分がどんどん蒸散していきます。すると、表面だけが「縮もう」とする力が働きます。
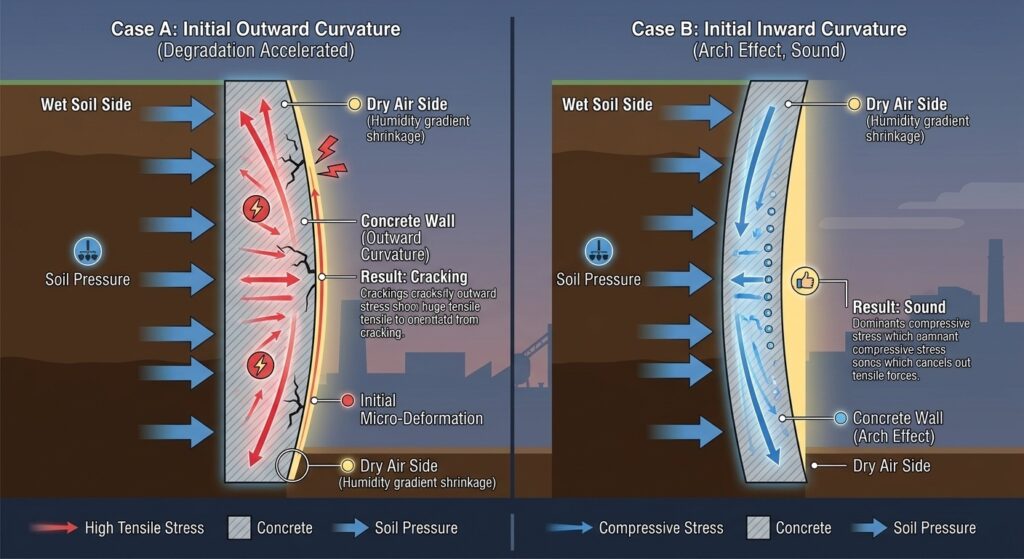
2-3. 「反り(ワーピング)」現象の発生 この「裏面は膨らみたい」「表面は縮みたい」という力の差が生じると、コンクリート板は自然と湿っている側を凸(外側へ膨らむ形)に、乾いている側を凹に 曲がろうとします。これを専門用語で「反り(ワーピング)」と呼びます。
コンクリート劣化のメカニズム 3. 【核心】「反れない」からこそ、コンクリートは悲鳴を上げる 3-1. 拘束状態がもたらす内部応力 もしコンクリートが空中に浮いていれば、単に「反る」だけで済みます。しかし、現実の構造物はそうはいきません。
土の重みによる押さえつけ 隣接する壁や柱との接続 地面との摩擦 これらによって「反り」が抑え込まれることを「拘束」と呼びます。反りたいのに反れないとき、コンクリート内部には凄まじい**「内部応力」**が発生します。
3-2. 引張強度の限界とひび割れ コンクリートは「押される力」には非常に強いですが、「引っ張られる力」には驚くほど脆い(圧縮強度の約1/10)という弱点があります。 反りを抑え込まれた結果、乾燥している表面側には「無理やり引き延ばされる力(引張応力)」が集中します。この力がコンクリートの限界を超えた瞬間、バリバリとひび割れが発生するのです。
4. なぜ「膨らんでいる」ように見えるのか? 読者の皆さんの中には、「ひび割れた部分が少し浮き上がって(膨らんで)見える」と感じる方もいるでしょう。これには明確な理由があります。
マイクロクラックの集合: 表面に無数の微細なひびが入ることで、組織がスカスカになり、見た目の体積が増えたように感じられます。裏面からの押し出し: 反りを抑え込んでいるとはいえ、裏面の膨張圧は消えていません。弱くなった表面のひび割れ部分を、裏面が押し出すような形になり、局所的な膨らみとして観察されます。鉄筋の錆(さび): ひび割れから水や酸素が入り込むと、中の鉄筋が錆びます。鉄筋は錆びると体積が2.5倍以上に膨らむため、これが内側からコンクリートを押し出し、「爆裂」と呼ばれる大きな膨らみと欠落を引き起こします。5. 被害を最小限に食い止めるための対策と管理 5-1. 設計・施工段階での対策 伸縮継手の適切な配置: 力を逃がす「逃げ道」を作っておく。湿潤養生の徹底: 急激な乾燥を防ぎ、初期の強度を十分に確保する。防水・透湿コントロール: 土に接する面の防水処理や、表面の乾燥を抑えるコーティング。5-2. 構造物ヘルスモニタリングの重要性 目視でひび割れが見つかった時には、すでに内部で深刻な劣化が進んでいることもあります。 最新の「構造物ヘルスモニタリング」では、センサーを用いて以下の項目をリアルタイムで監視します。
温湿度センサー: 表面と裏面の不均衡を早期に検知。歪みゲージ: 拘束によって生じている「目に見えないストレス」を計測。AE(アコースティック・エミッション)センサー: コンクリート内部でひび割れが発生する際の「音」を捉え、破壊の兆候を察知。まとめ:コンクリートの「声」を聴く コンクリートのひび割れや膨らみは、過酷な環境下で耐え続けている構造物からのサインです。 「片面が土、片面が空気」という環境は、私たちが思う以上にコンクリートにストレスを与えています。このメカニズムを理解し、適切な診断とメンテナンスを行うことが、大切な建物の寿命を延ばす唯一の道です。
もし、お住まいや管理物件で気になる兆候を見つけた場合は、単に表面を塗って隠すのではなく、その背後にある「湿度のドラマ」を疑ってみてください。
関連記事 



 追記:2026年4月更新──ダウングレード不可、YouTube側変更の隣
追記:2026年4月更新──ダウングレード不可、YouTube側変更の隣 まだなし → 2026/4/7には配信されたもよう
まだなし → 2026/4/7には配信されたもよう