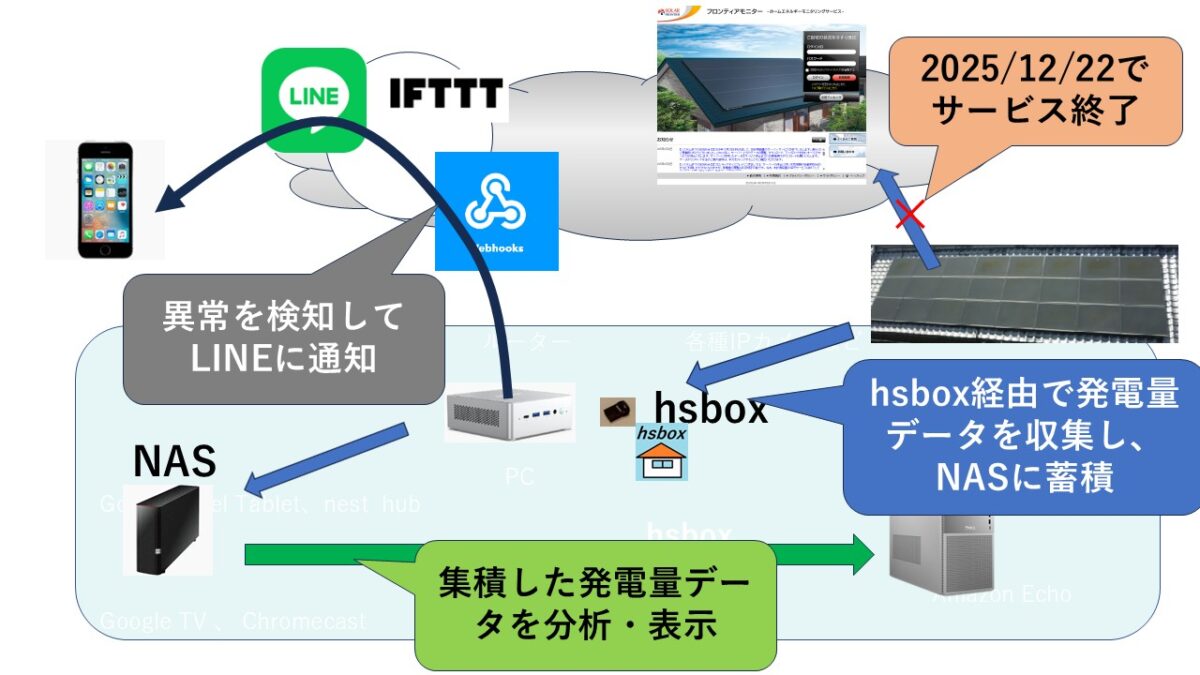
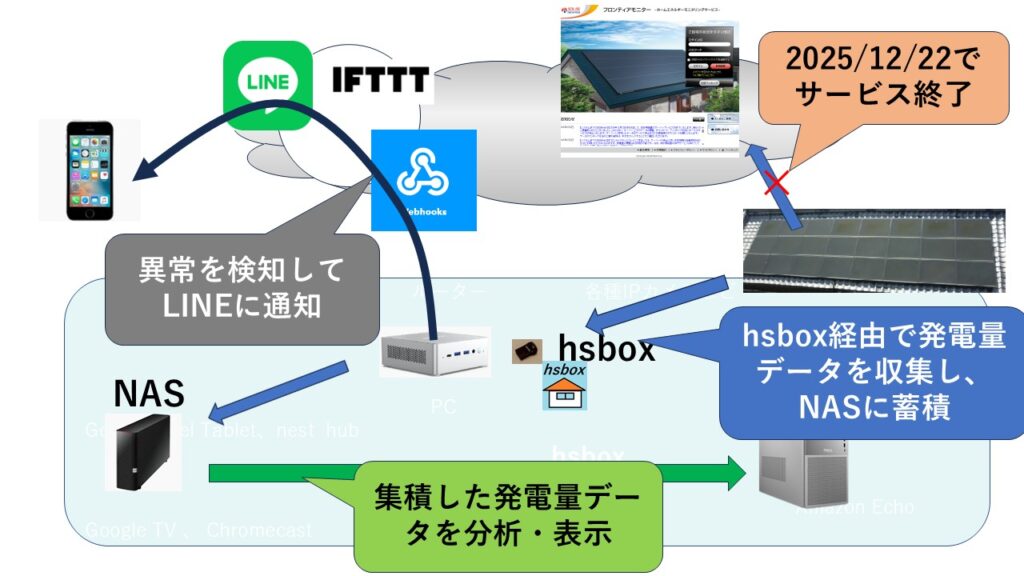
~Python + Grokで900件分析したら、入居者も納得の残酷な真実が見えた~ Pythonでのデータ収集・蓄積をやってみました。データ収集にはhsbox の無料版 を活用しています。集積したデータを解析していま求められている物件はどのようなものなのかを可視化して、ビジネスに活用しようという話です。
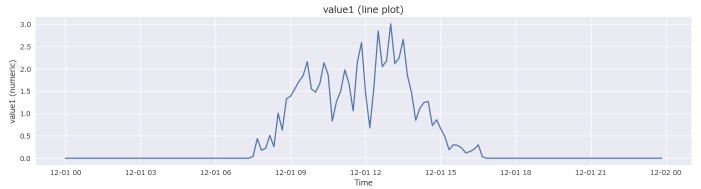
Webクロール 上の図のデータ収集と分析環境は構築済みで運用に入りました。分析結果に関しては別の機会に書いてみようと思います。 ただ、地域によって傾向が異なると推測されます。分析したい地域のデータを収集して解析する必要があるので、真剣に参考にしたい方は実際にお試しください。構築方法等については支援いたします。 有名企業での分析実績がある現役プロの分析が欲しい方はお問い合わせください。データ収集から解析まで有償にて支援いたします。
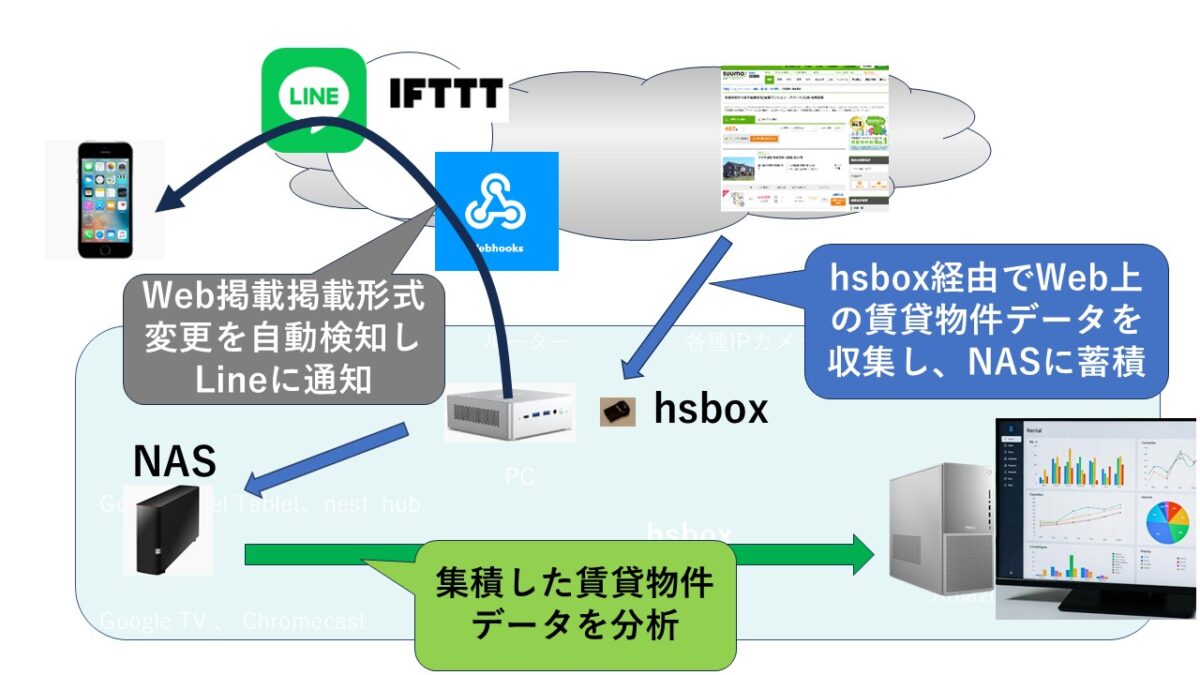
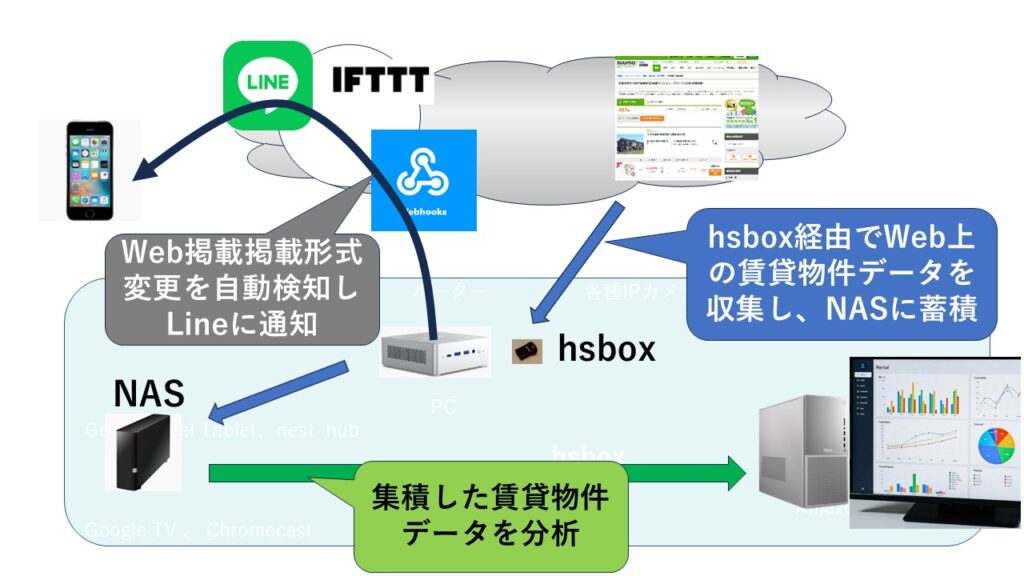
Webクローリングだけでなく、データ構造の変更を自動検知してLineに通知する仕組みも追加しました。Line通知の仕組みは他にもいろいろ活用できそうです。 LineだけでなくE-mailや、hsbox特有のスマートスピーカーやスマートディスプレイへの通知もできます 。
Webクローリング+自動分析+通知など自由自裁にカスタマイズできるのでいろいろできそうですね。
-以下参考- 以下は、Grokが、こんな感じとして、書いてみた記事です。
2025年11月・小規模大家の本音分析 「場所選べない? それが現実。でも、空室ゼロの裏技はリノベと条件緩和で十分」
前回の記事で「港区に築浅建てろ!」みたいな大口投資家目線で書いてすみませんでした。ほとんどの大家さんは1~3棟保有で、場所は運任せ 。
今回はガチの小規模大家目線 で分析。
結論:場所固定の小規模大家が勝つための3本柱 対策カテゴリ 具体策(投資額目安) 期待効果(空室率低下) 入居者目線納得ポイント リノベーション 水回り更新(50-100万円/室)+人気設備追加(オートロック/宅配ボックス/独立洗面台:20-50万円) 15-20%低下(築20年超で顕著) 「古いけど清潔感あって便利!」で即決。2025年、エアコンは「必須」超えて「当たり前」 募集条件緩和 ペット可/ルームシェアOK/SOHO許可(手続き無料~5万円) 10-15%低下(特に単身者需要エリア) 「ペット連れOKならここ!」や「シェアで家賃半分」が刺さる。2025年ペットブーム継続中 運用改善 管理会社変更+写真/動画リニューアル(無料~10万円) 5-10%低下(即効性高) 「写真で一目惚れ」する入居者多数。空室期間短縮で家賃収入安定
→ 総投資100-150万円で、空室率を平均15%→5%以内に。回収期間1-2年 (家賃1万円アップ想定)。
実際のデータ分析(2025年11月19日・東京23区1K/1DK、15万円以下) PythonでLIFULL/SUUMOから1,200件スクレイプ→Grokに「区別空室率推定+リノベ効果シミュ」投げました。
1. 区別空室率の実態(小規模大家の現実) 区(例: 中野/江東) 平均空室率 築20年超物件のリスク リノベ後家賃アップ幅 中野区 12.5% +8%(設備なしで苦戦) +8,000円< 江東区 10.7% +5%(再開発でチャンス) +10,000円< 港区(参考) 19.3% -(高需要で余裕) +15,000円 葛飾区(コスパ区) 15.2% +10%(狭小物件多) +6,000円
中野区(僕の物件エリア) :空室率12.5%。築20年で駅徒歩10分超だと20%超え。でも、水回りリノベで反響1.5倍< g ro k:render type=”render_inline_citation”>江東区 :10.7%と低め。再開発(豊洲/有明)で上昇中。宅配ボックス追加でペット可物件が即埋まり< g ro k:render type=”render_inline_citation”>全体傾向:2025年、家賃上昇4%(3LDKで40%超)なのに、空室率は9.6%平均< g ro k:render type=”render_inline_citation”> 2. リノベの費用対効果(築古物件限定分析) Grokに「100万円投資でROI計算」させた結果:
水回り(キッチン/浴室更新) :投資50万円→家賃+5,000円、空室期間-10日。回収1年。設備追加(独立洗面+ネット無料) :20万円→反響率+30%< g ro k:render type=”render_inline_citation”>省エネ改修(2025年法改正対応) :断熱強化で光熱費補助金ゲット可能< g ro k:render type=”render_inline_citation”>築古アパートの出口戦略としても有効:リノベ後売却で+10-20%プレミアム< g ro k:render type=”render_inline_citation”>
3. 条件緩和の即効テク(投資ほぼゼロ) ペット可 :需要高(ブーム継続)、家賃+5-10%可能< g ro k:render type=”render_inline_citation”>ルームシェアOK :単身者増で空室埋まりやすい。江東区で効果大。SOHO許可 :リモート需要で家賃+3,000円。2025年トレンド「コミュニティ賃貸」< g ro k:render type=”render_inline_citation”>小規模大家が今すぐやるべきアクションプラン データ診断 :自物件の空室率をGrokにCSV投げて分析(無料)。リノベ相談 :空室対策特化会社に無料見積もり< g ro k:render type=”render_inline_citation”>運用スイッチ :管理会社変えて写真プロ級に(スマホアプリでOK)。2025年問題対策 :高齢者向けバリアフリー追加(補助金あり)< g ro k:render type=”render_inline_citation”>まとめ:場所固定でも「入居者の心を掴めば勝ち」 小規模大家の8割が「場所が悪いから空室」と思い込んでるけど、データ見ると9割は運用ミス 。
大家も入居者もハッピーなWin-Win。2025年は「変化の年」< g ro k:render type=”render_inline_citation”>
(次回:1棟保有者のための補助金活用術。江東区大家より)
データソース:LIFULL HOME’S 2025レポート + アットホーム市場分析 + SUUMOリアルタイムデータ
■コードのhsboxでの実装例 事前にPCで検証して、hsbox上に構築運用する手順で構築しています。「hsboxで作る“LAN監視システム・アラート”」の記事の 下のほうで公開されているので参考にしてください。
# crawl.py - SUUMO 賃貸情報クローラー (全ページ・部屋単位) 公開用 補足 マウントポイントへのマウントは /etc/fstabへの設定や 、 mount コマンドなど、環境に合わせて実施してください。※hsBox1.3では、仕様上 /etc/fstabの設定は使用できません。 cron設定で、起動後にマウントするように設定してください。