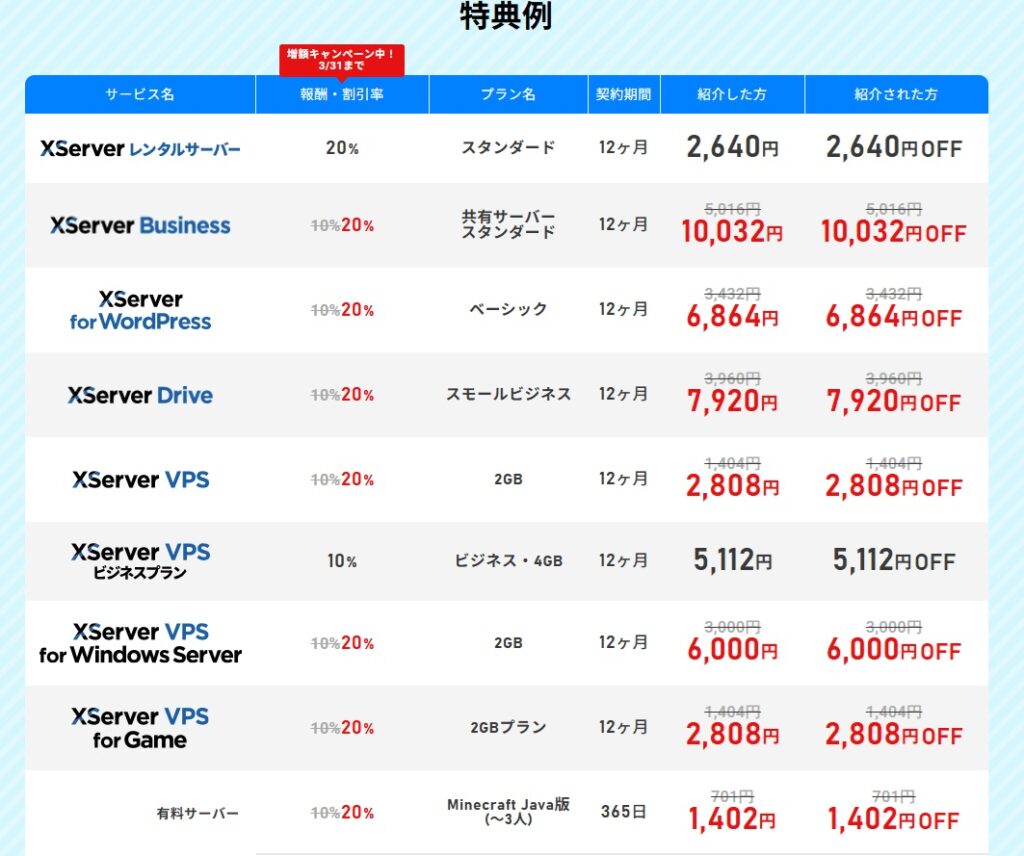
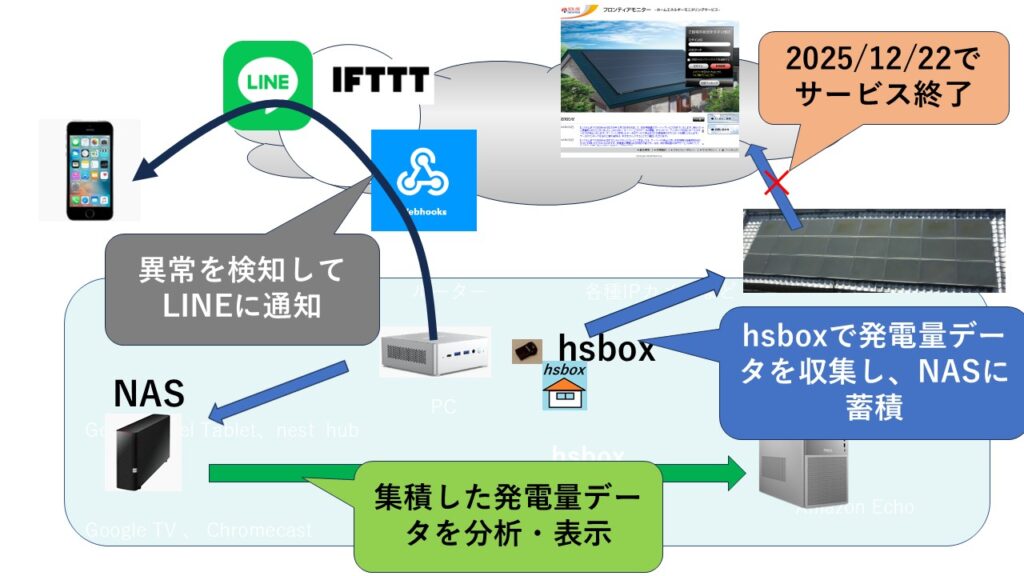
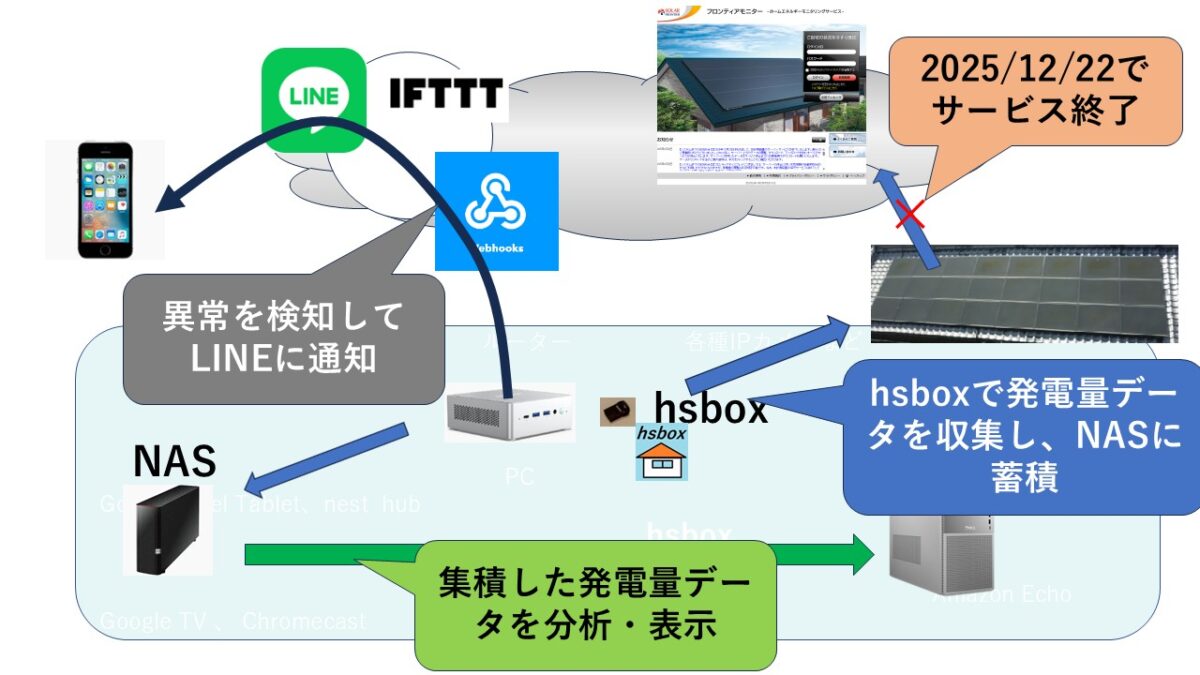
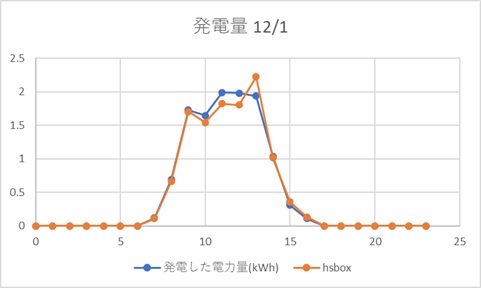
hsbox の proxy実装 の続きをしましょう。 httpは通りました https対応に挑戦です。
確認方法の検討 $ curl -I http: //github.com 301 Moved Permanently curl -I https: //github.com 200 guithub.comのトップでhttpsへのプロキシが効くが確認することにします。
最初の状態 でのProxy動作を確認してみます
$ curl -x http://192.168.2.45:8080 http://github.com 何も応答がありません。
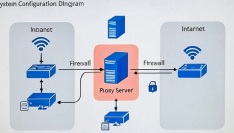
プロキシをとおしてプロキシでポストデータを取得するのが目的です。 この場合、POSTはhttpsではなくhttpで送られる必要があるでしょう。そして、プロキシでhttpsに変換する。 そのような使い方をしたいので、 mitmproxy の 設定方法を変更します。
mitmproxy 用解析・保存スクリプトを更新配置(仮2) ■/home/hsbox/pyd/fm_capture.py を更新配置 (内容は以下) systemd サービスファイルの更新 [Unit]ユーザー名:パスワード@ --script /home/hsbox/pyd/fm_capture.py --quiet ※ユーザー名とパスワード を設定してください。 使用しない場合、”–proxyauth”の設定は不要です。
動作確認 ■curlで、 動作検証します。 curl -x http://<プロキシが動作するhsboxのIP>:8080 http://github.com/ curl -x http://192.168.1.10:8080 http://github.com ※これで、proxyで、httpをhttpsに変換してアクセスできていそうです。 NAS設定の修正 11月 28 23:03:07 hsbox systemd[1]: Started Frontier Monitor Transparent Proxy.
NASの書き込み権限がないため書き込めません、mitmproxyは、hsbox権限で起動しているので、権限を777に設定します。また、暫定対処ですが、起動時に自動マウントするように以下のマウントコマンドを仕込んでおきました。 ※事前に手動実行で操作確認しておいてください
# mitmproxy 用 NAS マウント mitmproxy 用解析・保存スクリプトを更新配置(仮3) キャプチャデータをローカルおよびNASに保存するスプリプとに更新します。
#!/usr/bin/env python3 手動でポストをシミュレーションして動作確認 httpsのサイトに手動でポストしてみたデータを保存できるか検証します
~$ curl -x http://<hsBoxのIP>:8080 --insecure -X POST -d "test=2111 " http://github.com 保存されたデータを確認 {“ts”: “2025-11-29T10:13:24.269169”, “host”: “github.com”, “url”: “https://github.com/”, “post”: “test=11111&name=%C3%A3%C2%83%C2%95%C3%A3%C2%83%C2%AD%C3%A3%C2%83%C2%B3%C3%A3%C2%83%C2%86%C3%A3%C2%82%C2%A3%C3%A3%C2%82%C2%A2”}{“ts”: “2025-11-29T10:52:06.845328”, “host”: “github.com”, “url”: “https://github.com/”, “post”: “test=21111&name=%C3%A3%C2%83%C2%95%C3%A3%C2%83%C2%AD%C3%A3%C2%83%C2%B3%C3%A3%C2%83%C2%86%C3%A3%C2%82%C2%A3%C3%A3%C2%82%C2%A2 “}
1回のポストで1行追加されました。
ポストしたデータが丸ごと入っていることを確認できました。
ハードルが複数あるので、着実に1つづつクリアしていくのが、近道でしょう。
・–quiet にしないとサービス起動できない
簡単にまとめると権限問題とタイミング問題ですね。開発者あるあるですね。。
関連記事