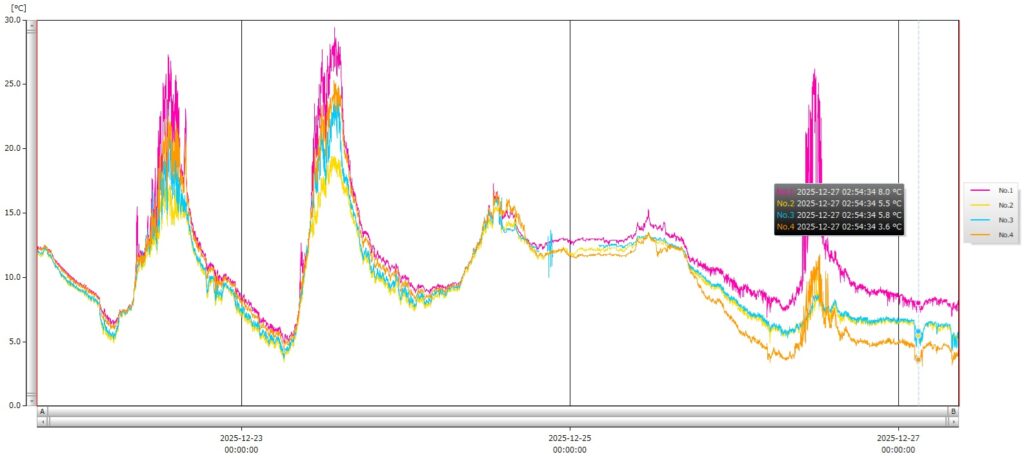
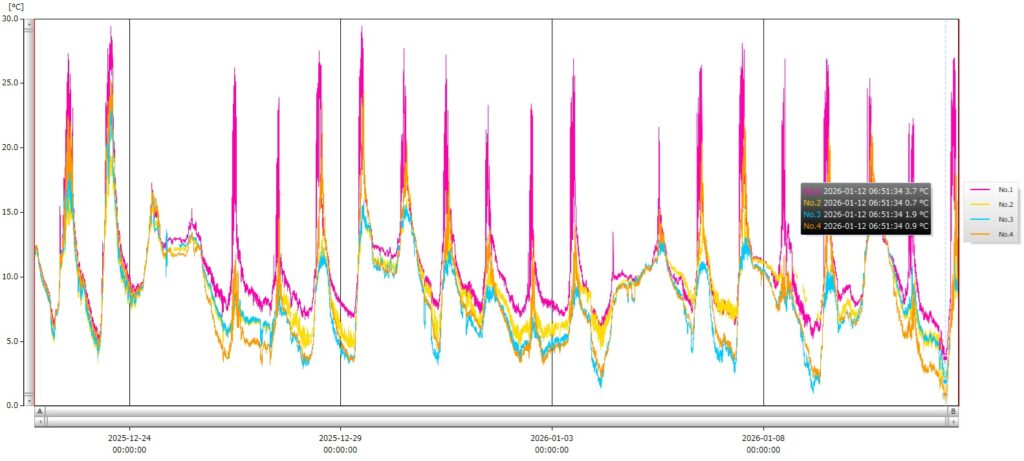
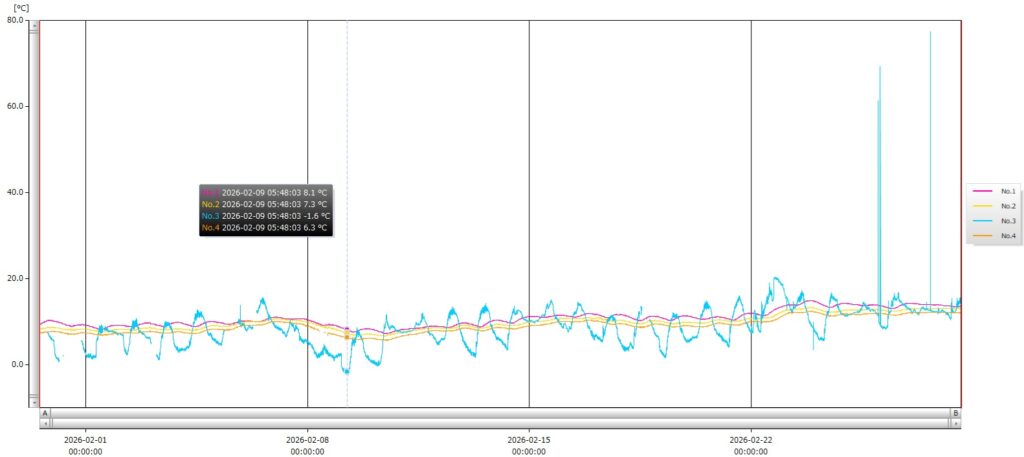
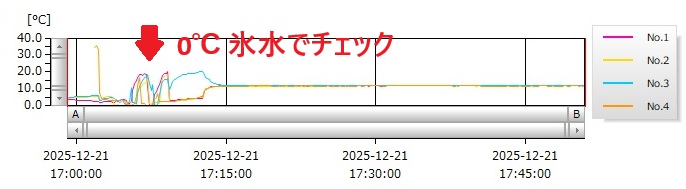
前回までで、センサーから信号をとりだすアナログ部分の仮構築が完了しました。ここからは、取り出したAE信号をAD変換してロギングする部分を構築していきます。
前出(アナログ部製作編)の採用するシステム構成の方針により、ロギングシステムの中核につぎのパーツを採用しました。
AD変換&ロギング部
[107385]Arduino Uno Rev3
https://akizukidenshi.com/catalog/g/g107385/

事前検討方針
ドキュメントレベルの調査結果から、次の課題があることを確認しました。
・USBケーブル挿抜で再起動される(運用上、 通常ロギング時は単体で動作し、データ吸い上げ時だけUSB接続する運用にする必要がある)
・再起動でRAMはリセットされ、EEPROMはリセットされないが書き込み回数上限制限がある(カウンタ等の頻繁に更新される変数保存ができない)
・EEPROMの容量が小さい(長期間ロギングのため、できるだけ大きいデータ領域を確保したい)
これらの問題を、解決する必要があります。そこで2つめと3つめの課題は、次回検討するプログラミング実装レベルで解決することにしました。ここでは、USBケーブル挿抜に関わる挙動の確認と対策、そして再起動されていないかどうかについて確認する方法を検討することにしました。
Arduino IDE をインストールするPCのスペック確認
Arduino IDE に必要なスペックを確認しておく。Windows 10以降のPCならほぼ大丈夫。
問題なければ、インストール。
Arduino 公式ソフトウェアページ
動作確認
PCにArduinoを繋ぎ、デバイスマネージャーの「ポート(COMとLPT)」に「Arduino Uno」が表示されるか確認する。
USBを挿す前は Port のさきに COM3などが見えていましたが、 USBをさすとPortがグレーアウトされました。
Board: ”Arduino Uno” → Arduino AVR Boardsで Arduino Unoを選択しました。
→ これでは、まだ認識していないようです。
USBを一度抜挿して確認、これでもまだ認識していないようだが、 再度開きなおすと
下のキャプチャのようにCOM4(Arduino Uno)が表示される。
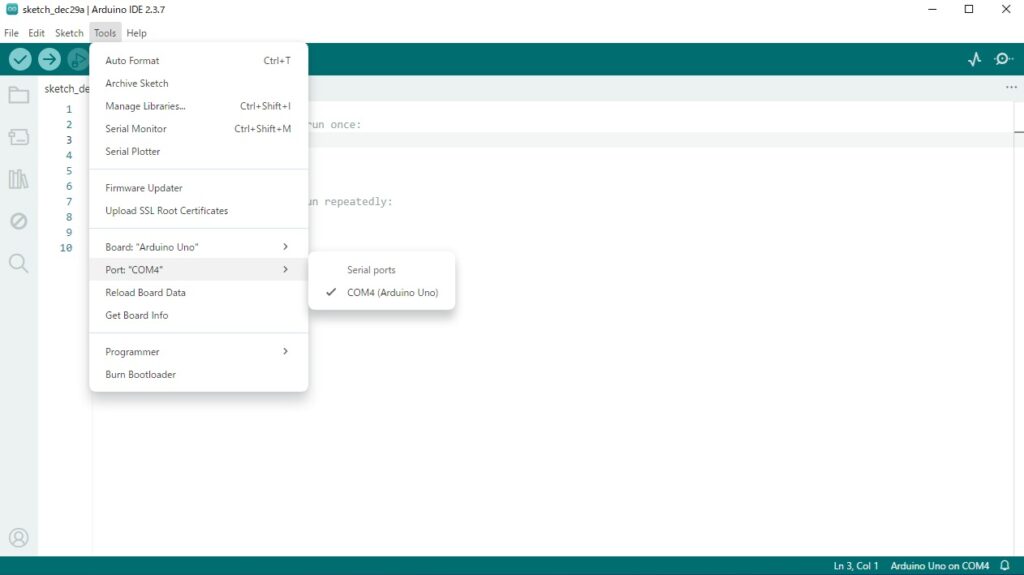
最初の動作確認
出荷時は、次のサンプルが動いているようです。
サンプルを開く:
「ファイル」→「スケッチ例」→「01.Basics」→ 「Blink」
delay(100); など、任意の時間に変更して、
再度、画面左上の 「→(書き込み)」ボタン を押すと、コードを書き込んで点滅間隔がかわる。
Arduino Unoの動作状況確認
Arduino Unoは基本1方向らしい、吸出しなどはavrdude コマンドらしい。
“C:\Program Files (x86)\Arduino\hardware\tools\avr\bin\avrdude.exe” -C “C:\Program Files (x86)\Arduino\hardware\tools\avr\etc\avrdude.conf” -v -p atmega328p -c arduino -P COM4 -b 115200 -U flash:r:backup.hex:i
ユーザーパスにインストールしていたので、avrdude.exeは次のパスにありました。
C:\Users\<ユーザー名>demo\AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17\bin
パラメータを確認
> .\avrdude.exe -?
Usage: avrdude.exe [options]
Options:
-p <partno> Required. Specify AVR device.
-b <baudrate> Override RS-232 baud rate.
-B <bitclock> Specify JTAG/STK500v2 bit clock period (us).
-C <config-file> Specify location of configuration file.
-c <programmer> Specify programmer type.
-D Disable auto erase for flash memory
-i <delay> ISP Clock Delay [in microseconds]
-P <port> Specify connection port.
-F Override invalid signature check.
-e Perform a chip erase.
-O Perform RC oscillator calibration (see AVR053).
-U <memtype>:r|w|v:<filename>[:format]
Memory operation specification.
Multiple -U options are allowed, each request
is performed in the order specified.
-n Do not write anything to the device.
-V Do not verify.
-u Disable safemode, default when running from a script.
-s Silent safemode operation, will not ask you if
fuses should be changed back.
-t Enter terminal mode.
-E <exitspec>[,<exitspec>] List programmer exit specifications.
-x <extended_param> Pass <extended_param> to programmer.
-y Count # erase cycles in EEPROM.
-Y <number> Initialize erase cycle # in EEPROM.
-v Verbose output. -v -v for more.
-q Quell progress output. -q -q for less.
-l logfile Use logfile rather than stderr for diagnostics.
-? Display this usage.
avrdude version 6.3-20190619, URL: <http://savannah.nongnu.org/projects/avrdude/>
■flash(プログラム領域)の吸い上げ の試行
※参考にする場合はパス(特に赤字)を環境に合わせてください。
.\avrdude.exe "-CC:\Users\<ユーザ名>\AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17/etc/avrdude.conf" -v -p atmega328p -c arduino "-PCOM4" -b115200 -U flash:r:backup.hex:i
avrdude.exe: Version 6.3-20190619
Copyright (c) 2000-2005 Brian Dean, http://www.bdmicro.com/
Copyright (c) 2007-2014 Joerg Wunsch
System wide configuration file is "C:\Users\<ユーザ名>\AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17/etc/avrdude.conf"
Using Port : COM4
Using Programmer : arduino
Overriding Baud Rate : 115200
AVR Part : ATmega328P
Chip Erase delay : 9000 us
PAGEL : PD7
BS2 : PC2
RESET disposition : dedicated
RETRY pulse : SCK
serial program mode : yes
parallel program mode : yes
Timeout : 200
StabDelay : 100
CmdexeDelay : 25
SyncLoops : 32
ByteDelay : 0
PollIndex : 3
PollValue : 0x53
Memory Detail :
Block Poll Page Polled
Memory Type Mode Delay Size Indx Paged Size Size #Pages MinW MaxW ReadBack
----------- ---- ----- ----- ---- ------ ------ ---- ------ ----- ----- ---------
eeprom 65 20 4 0 no 1024 4 0 3600 3600 0xff 0xff
flash 65 6 128 0 yes 32768 128 256 4500 4500 0xff 0xff
lfuse 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
hfuse 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
efuse 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
lock 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
calibration 0 0 0 0 no 1 0 0 0 0 0x00 0x00
signature 0 0 0 0 no 3 0 0 0 0 0x00 0x00
Programmer Type : Arduino
Description : Arduino
Hardware Version: 3
Firmware Version: 4.4
Vtarget : 0.3 V
Varef : 0.3 V
Oscillator : 28.800 kHz
SCK period : 3.3 us
avrdude.exe: AVR device initialized and ready to accept instructions
Reading | ################################################## | 100% 0.02s
avrdude.exe: Device signature = 0x1e950f (probably m328p)
avrdude.exe: safemode: lfuse reads as 0
avrdude.exe: safemode: hfuse reads as 0
avrdude.exe: safemode: efuse reads as 0
avrdude.exe: reading flash memory:
Reading | ################################################## | 100% 5.22s
avrdude.exe: writing output file "backup.hex"
avrdude.exe: safemode: lfuse reads as 0
avrdude.exe: safemode: hfuse reads as 0
avrdude.exe: safemode: efuse reads as 0
avrdude.exe: safemode: Fuses OK (E:00, H:00, L:00)
avrdude.exe done. Thank you.
上の実行の結果、ファイルが実行パスに出力されていることを確認しました。
面白くなってきました。
このファイルのサイズは78KBで、テキストエディターでも見える形式です。
行頭に”:”があり4byte分アドレス相当の情報、実データ、最後に1byteチェックサムがついているようですね。
つぎにEEPROMの中身を読みだしてみます。
> .\avrdude.exe "-CC:\Users\<ユーザ名>\AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17/etc/avrdude.conf" -v -p atmega328p -c arduino "-PCOM4" -b115200 -U eeprom:r:eeprom.hex:i
avrdude.exe: Version 6.3-20190619
Copyright (c) 2000-2005 Brian Dean, http://www.bdmicro.com/
Copyright (c) 2007-2014 Joerg Wunsch
System wide configuration file is "C:\Users\<ユーザ名>\AppData\Local\Arduino15\packages\arduino\tools\avrdude\6.3.0-arduino17/etc/avrdude.conf"
Using Port : COM4
Using Programmer : arduino
Overriding Baud Rate : 115200
AVR Part : ATmega328P
Chip Erase delay : 9000 us
PAGEL : PD7
BS2 : PC2
RESET disposition : dedicated
RETRY pulse : SCK
serial program mode : yes
parallel program mode : yes
Timeout : 200
StabDelay : 100
CmdexeDelay : 25
SyncLoops : 32
ByteDelay : 0
PollIndex : 3
PollValue : 0x53
Memory Detail :
Block Poll Page Polled
Memory Type Mode Delay Size Indx Paged Size Size #Pages MinW MaxW ReadBack
----------- ---- ----- ----- ---- ------ ------ ---- ------ ----- ----- ---------
eeprom 65 20 4 0 no 1024 4 0 3600 3600 0xff 0xff
flash 65 6 128 0 yes 32768 128 256 4500 4500 0xff 0xff
lfuse 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
hfuse 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
efuse 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
lock 0 0 0 0 no 1 0 0 4500 4500 0x00 0x00
calibration 0 0 0 0 no 1 0 0 0 0 0x00 0x00
signature 0 0 0 0 no 3 0 0 0 0 0x00 0x00
Programmer Type : Arduino
Description : Arduino
Hardware Version: 3
Firmware Version: 4.4
Vtarget : 0.3 V
Varef : 0.3 V
Oscillator : 28.800 kHz
SCK period : 3.3 us
avrdude.exe: AVR device initialized and ready to accept instructions
Reading | ################################################## | 100% 0.02s
avrdude.exe: Device signature = 0x1e950f (probably m328p)
avrdude.exe: safemode: lfuse reads as 0
avrdude.exe: safemode: hfuse reads as 0
avrdude.exe: safemode: efuse reads as 0
avrdude.exe: reading eeprom memory:
Reading | ################################################## | 100% 3.11s
avrdude.exe: writing output file "eeprom.hex"
avrdude.exe: safemode: lfuse reads as 0
avrdude.exe: safemode: hfuse reads as 0
avrdude.exe: safemode: efuse reads as 0
avrdude.exe: safemode: Fuses OK (E:00, H:00, L:00)
avrdude.exe done. Thank you.
eepromのデータを読み出せました。ファイルサイズは3kbです。ですが、中身はFlashメモリの冒頭部分と同じようでした。 確認のため、 eeprom_clearというサンプルをアップロードして確認してみます。→結果、再度読み込んだファイルの中身は、変わりませんでした。 上のEEPROMの読み出しは機能していないようです。失敗しているよう。
サンプルに、eeprom_clearや eeprom_readがあるのでこれを使ってみます。eeprom_readをアップロードして確認してみます。右上のシリアルモニタとシリアルプロッタを使って、確認すると。EEPROMの1kb分が0で帰ってきました。
基本的な動きが確認できたので、ここでの検証課題のUSB挿抜でのリセット発生状況の確認と回避確認です。
と、ここで、想定外の情報、「Arduino IDE(PC側)のシリアルモニタを開く操作をすると、Arduinoボード本体に自動的にリセットがかかる」らしい、USB挿抜以外にもチェックするべき観点が増えた。
要約すると、おもに電源に関連する不安定要素によるものと、 通信制御によるリセットの2つで、通信制御によるものはUSB挿抜と、DTR/RTS信号によるオートリセットということらしい。電源に関してはACアダプターでの安定供給と、シールド対策をするとして、USB挿抜とDTR/RTS信号によるリセットされることについては「 RESET-GND間に10μFのコンデンサを挟む」対策をする。
さて、要因は1つ増えたが、対策は増えていないので、方針は変えずに先に進めよう。
さらに追加情報をみつけた、「リセット理由の切り分けは MCUSR (MCU Status Register) レジスタ」でできるらしい。
MCUSRレジスタのビットマップ解説
このレジスタの 下位4ビット がリセット要因を示します。
ビット番号 ビット名 名称 内容
Bit 3 WDRF ウォッチドッグ・リセット ウォッチドッグタイマーのタイムアウトによるリセット
Bit 2 BORF ブラウンアウト・リセット 電源電圧が規定値を下回ったことによるリセット(電源不安定が原因)
Bit 1 EXTRF 外部リセット RESETピンを「LOW」にしたことによるリセット(DTR信号/物理ボタンが原因)
Bit 0 PORF パワーオン・リセット 電源が完全にOFFの状態からONになった時のリセット
本番向け実装も考慮して、MCUSRレジスタも含めてデータ構造設計をします。方針は、あらかじめデータ保存領域を00クリアしておきます。データ登録はブロック単位でおこない、更新は追記のみで上書きはしないものとします。
データブロック構造を次のように定義する。
00 00 00 00 00
最初の1byteを、種別フラグとする。
意味を次のようにする。
00: 未使用
01: リセットデータ
2byte目:MCUSRレジスタ
02: 同期データ
2byte目:クロックタイマー
6?byte目:時刻データ
03: 未定義
1x: チャンネルデータ
2byte目:クロックタイマー
6?byte目:AD変換データ
とりあえず、LED点滅回数でリセット回数が分かるようにしましょう
時刻データは、PCから受信を想定しています。
EEPROMの容量と1ブロックのサイズは、クロックタイマー+時刻データと クロックタイマー+AD変換データのうちの大きいほうを採用して決めます
LED点滅による通知仕様
リセット回数が5回なら 0.2秒間隔で5回点滅した後、2秒消えた後、5回点滅という繰り返しにします。
できるだけ長期間のロギングをしたいために、無駄なデータ領域を消費しないようにする。
なお、リセット回数は、 EEPROMにどこまで書き込まれたかとリセット回数をカウントアップして保持して、データ追加と点滅回数に使用します
1ブロック 8バイト固定の決定案
Unix Timeは4バイト(32bit)すべてを格納。
| バイト | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 備考 |
|---|---|---|---|---|---|---|---|---|---|
| 01 (Reset) | 01 | MCUSR | <— | millis(4B) | —> | 00 | 00 | 最もシンプルな構成 | |
| 02 (Sync) | 02 | <— | Unix Time(4B) | —> | <— | millis(4Bの一部) | —> | ※後述 | |
| 1x (Data) | 1x | 00 | <— | millis(4B) | —> | <— | AD値(2B) | —> |
1. EEPROM走査関数: 起動時に先頭から8バイトずつ読み、01の数を数えつつ、最初の00を見つける。
2. リセット記録: setup()の最初で01レコード(MCUSR付き)を追記。
3. LED点滅関数: loop()内でmillis()を監視し、カウントされた回数分だけ点滅(delayを使わない)。
4. PC同期受信: シリアルで 0x02 を受信したら、続く4バイトをUnix Timeとして処理。
※補足:3ヶ月ロギングで1KBのEEPROM(128回分)が溢れるのが心配な場合は、追記時に「これ以上書かない」というガードも入れる。
1.書き込み位置特定: 8バイトすべてが 0x00(完全な未使用領域)であることを条件に、追記位置を決定します。
2.時刻同期(02): PCから [0x02][UnixTime 4B][CheckSum 1B] の計6バイトを受信する仕様とします。チェックサムはUnixTime 4バイトの加算下位1バイトとします。
3.データ構造の遵守:
1. 01(Reset): [01][MCUSR][00 00 00 00 00 00] (計8バイト)
2. 02(Sync): [02][UnixTime 4B][millis 3B(上位)]
※02にのみ、PC時刻とArduino内時計を紐付けるための基準点としてmillisを保持します。
ここまで作業が進んだところで、EEPROMの読み込み問題に気が付いたので先に書いた対策を実施しました。詳しくはこちらを参照してください→「Arduino Uno 事前検証過程(その3の1)でのEEPROM読み出し問題の回避策」
本体実装 (Arduinoスケッチ ResetDetector.ino)
まず、リセットと同期の実装を入れた実験版です。
/*
* Reset logging PreCode
*/
#include <EEPROM.h>
#include <avr/wdt.h>
// --- 定数定義 ---
const int BLOCK_SIZE = 8;
const int EEPROM_LIMIT = 1024;
const int LED_PIN = 13;
int totalResetCount = 0;
int nextAddr = 0;
byte lastMcusr = 0;
void setup() {
lastMcusr = MCUSR;
MCUSR = 0; // 次回のためにクリア
Serial.begin(9600);
pinMode(LED_PIN, OUTPUT);
// 1. 書き込み位置の特定(全8バイトが0x00であることを確認)
findNextAddrAndCount();
// 2. リセット記録(設計案通り、millisを含まない構成)
recordReset();
}
void loop() {
updateLED(); // LED点滅処理(非ブロッキング)
checkSerial(); // PCからの同期信号(02)待ち
}
// 課題1:書き込み位置特定(種別00かつ全データ00を判定)
void findNextAddrAndCount() {
nextAddr = -1;
totalResetCount = 0;
for (int i = 0; i < EEPROM_LIMIT; i += BLOCK_SIZE) {
bool allZero = true;
byte type = EEPROM.read(i);
if (type == 0x01) totalResetCount++;
// 全8バイトが0x00かチェック
for (int j = 0; j < BLOCK_SIZE; j++) {
if (EEPROM.read(i + j) != 0x00) {
allZero = false;
break;
}
}
if (allZero && nextAddr == -1) {
nextAddr = i;
}
}
if (nextAddr == -1) nextAddr = 0; // 満杯時は先頭(運用に合わせて要調整)
}
// 課題4:当初案通りのリセット記録(余計なmillisは排除)
void recordReset() {
if (nextAddr + BLOCK_SIZE > EEPROM_LIMIT) return;
EEPROM.update(nextAddr, 0x01); // 種別フラグ
EEPROM.update(nextAddr + 1, lastMcusr); // MCUSR(補助情報)
for (int i = 2; i < BLOCK_SIZE; i++) {
EEPROM.update(nextAddr + i, 0x00); // 残りは00埋め
}
nextAddr += BLOCK_SIZE;
// 点滅用にカウントを更新
totalResetCount++;
}
// 課題2:時刻同期(チェックサム付き)
void checkSerial() {
if (Serial.available() >= 6) {
if (Serial.read() == 0x02) {
uint32_t unixTime = 0;
byte checksum = 0;
for (int i = 0; i < 4; i++) {
byte b = Serial.read();
unixTime |= ((uint32_t)b << (i * 8));
checksum += b;
}
byte receivedSum = Serial.read();
if (checksum == receivedSum) {
saveSyncData(unixTime);
Serial.println("OK: Sync Success");
} else {
Serial.println("Error: Checksum Mismatch");
}
}
}
}
void saveSyncData(uint32_t ut) {
if (nextAddr + BLOCK_SIZE > EEPROM_LIMIT) return;
uint32_t currentMs = millis();
EEPROM.update(nextAddr, 0x02); // 種別フラグ
// UnixTime (4byte) を記録
for (int i = 0; i < 4; i++) {
EEPROM.update(nextAddr + 1 + i, (ut >> (i * 8)) & 0xFF);
}
// millis() の上位3バイトを記録 (Byte 5, 6, 7)
// 下位8bit(0-255ms)を切り捨てることで、0.25秒精度の同期を実現
EEPROM.update(nextAddr + 5, (currentMs >> 8) & 0xFF);
EEPROM.update(nextAddr + 6, (currentMs >> 16) & 0xFF);
EEPROM.update(nextAddr + 7, (currentMs >> 24) & 0xFF);
nextAddr += BLOCK_SIZE;
Serial.println("OK: Sync Data Recorded (0.25s precision)");
}
void updateLED() {
static unsigned long lastUpdate = 0;
static int flashStep = 0;
static int currentFlash = 0;
static bool pausing = false;
unsigned long now = millis();
if (pausing) {
if (now - lastUpdate >= 2000) {
pausing = false;
currentFlash = 0;
lastUpdate = now;
}
return;
}
if (now - lastUpdate >= 200) {
lastUpdate = now;
if (currentFlash < totalResetCount) {
digitalWrite(LED_PIN, !digitalRead(LED_PIN));
flashStep++;
if (flashStep >= 2) {
flashStep = 0;
currentFlash++;
}
} else {
digitalWrite(LED_PIN, LOW);
pausing = true;
}
}
}
同期実装(PowerShell sync.ps1)
同期処理を行うのに使用します。 ファイルを右クリックして、「PowerShellで実行」をくちっくして使用します
$ErrorActionPreference = "Stop" # 全てのエラーを「中断(catchに飛ばす)」対象にする
# --- 設定項目 ---
$portName = "COM4" # Arduinoが接続されているポートを確認して変更してください
$baudRate = 9600
try {
# シリアルポートの初期化
$port = New-Object System.IO.Ports.SerialPort($portName, $baudRate, "None", 8, "One")
$port.Open()
Start-Sleep -Seconds 2 # Arduinoのリセット待ち(DTRによるリセット対策)
# 1. 現在のUnix Time(1970/1/1からの経過秒)を取得
$unixTime = [DateTimeOffset]::Now.ToUnixTimeSeconds()
# 2. 4バイトのバイナリ配列に変換 (リトルエンディアン)
$utBytes = [BitConverter]::GetBytes([uint32]$unixTime)
# 3. チェックサムの計算 (4バイトの加算下位1バイト)
[byte]$checksum = 0
foreach ($b in $utBytes) {
$checksum = ($checksum + $b) -band 0xFF
}
# 4. 送信データの組み立て [0x02] + [Data 4B] + [Checksum 1B]
[byte[]]$sendBuffer = @(0x02) + $utBytes + @($checksum)
# 5. 送信
$port.Write($sendBuffer, 0, $sendBuffer.Length)
Write-Host ("送信成功: UnixTime = {0} (CheckSum: 0x{1:X2})" -f $unixTime, $checksum)
Write-Host ("送信バイナリ: " + [System.BitConverter]::ToString($sendBuffer))
# Arduinoからの応答("OK: Sync Success"など)を確認
Start-Sleep -Milliseconds 500
if ($port.BytesToRead -gt 0) {
$response = $port.ReadExisting()
Write-Host "Arduino応答: $response"
}
}
catch {
Write-Error "エラーが発生しました: $_"
}
finally {
if ($port -and $port.IsOpen) {
$port.Close()
Write-Host "ポートを閉じました。"
}
}
# --- スクリプトの最後に追加 ---
Write-Host "`nEnterキーを押すと終了します..."
Read-Host
実験結果
同期処理の実行結果は次の通り
送信成功: UnixTime = 1767166738 (CheckSum: 0xA2)
送信バイナリ: 02-12-D3-54-69-A2
Arduino応答: OK: Sync Data Recorded (0.25s precision)
OK: Sync Success
ポートを閉じました。
Enterキーを押すと終了します...
リセットの発生状況の検証を実施しました。 USBの挿抜では、リセットは発生していないようです。
9V ACアダプタ電源のコンセント抜き差しでも、リセット発生していません。電源供給の9V ACアダプタとUSBの切り替えがうまくいっているようです。つまり、ここまでは、LEDの点滅が1回の状態が続いています。
つぎに、USBと9V ACアダプタ電源のコンセント両方を抜きました。再度刺したところで、LEDは2回点滅に変わりました。これは、想定どおりです。ということで、USBの挿抜でのリセット発生は必ず起こるものではなさそうです。
このあと、一度同期をおこなって、追加で「DTR/RTS信号によるオートリセット」を強制的に行ってみます。
検証用コード (PowerShell: reset.ps1)
# --- 設定 ---
$portName = "COM4"
$baudRate = 115200
try {
# 1. ポートの初期化
$port = New-Object System.IO.Ports.SerialPort($portName, $baudRate, "None", 8, "One")
# 2. ポートを開く (この時点で多くのボードは一度リセットされます)
$port.Open()
Write-Host "Port $portName Opened."
# 3. DTR/RTSを操作して明示的にリセットをかける
# 一旦両方をFalse(High電位)にしてからTrue(Low電位)にする
Write-Host "Resetting Arduino..."
$port.DtrEnable = $false
$port.RtsEnable = $false
Start-Sleep -Milliseconds 200 # 信号を安定させるための待ち時間
$port.DtrEnable = $true
$port.RtsEnable = $true
Write-Host "Reset signal sent."
# 4. ブートローダーが立ち上がるまで少し待つ
Start-Sleep -Seconds 2
Write-Host "Arduino should be restarted now."
}
catch {
Write-Error "Error: $($_.Exception.Message)"
}
finally {
if ($port -and $port.IsOpen) {
$port.Close()
Write-Host "Port Closed."
}
}
Write-Host "Press Enter to exit..."
Read-Host
実行結果は次の通り。 このリセット後は、LEDの点滅は3回になりました。 設計通りの挙動です。 このあと、もう一度同期して一旦実験完了です。
Port COM4 Opened.
Resetting Arduino...
Reset signal sent.
Arduino should be restarted now.
Port Closed.
Press Enter to exit...
それでは、EEPROMにロギングした結果を吸い出して検証してみましょう。
:100000000100000000000000023AD25469D50F0040
:1000100001000000000000000212D35469CA000071
:10002000010000000000000002CCDD54697B0400E8
:1000300000000000000000000000000000000000C0
:1000400000000000000000000000000000000000B0
:1000500000000000000000000000000000000000A0
:100060000000000000000000000000000000000090
:100070000000000000000000000000000000000080
:100080000000000000000000000000000000000070
:100090000000000000000000000000000000000060
:1000A0000000000000000000000000000000000050
:1000B0000000000000000000000000000000000040
:1000C0000000000000000000000000000000000030
:1000D0000000000000000000000000000000000020
:1000E0000000000000000000000000000000000010
:1000F0000000000000000000000000000000000000
:1001000000000000000000000000000000000000EF
:1001100000000000000000000000000000000000DF
:1001200000000000000000000000000000000000CF
:1001300000000000000000000000000000000000BF
:1001400000000000000000000000000000000000AF
:10015000000000000000000000000000000000009F
:10016000000000000000000000000000000000008F
:10017000000000000000000000000000000000007F
:10018000000000000000000000000000000000006F
:10019000000000000000000000000000000000005F
:1001A000000000000000000000000000000000004F
:1001B000000000000000000000000000000000003F
:1001C000000000000000000000000000000000002F
:1001D000000000000000000000000000000000001F
:1001E000000000000000000000000000000000000F
:1001F00000000000000000000000000000000000FF
:1002000000000000000000000000000000000000EE
:1002100000000000000000000000000000000000DE
:1002200000000000000000000000000000000000CE
:1002300000000000000000000000000000000000BE
:1002400000000000000000000000000000000000AE
:10025000000000000000000000000000000000009E
:10026000000000000000000000000000000000008E
:10027000000000000000000000000000000000007E
:10028000000000000000000000000000000000006E
:10029000000000000000000000000000000000005E
:1002A000000000000000000000000000000000004E
:1002B000000000000000000000000000000000003E
:1002C000000000000000000000000000000000002E
:1002D000000000000000000000000000000000001E
:1002E000000000000000000000000000000000000E
:1002F00000000000000000000000000000000000FE
:1003000000000000000000000000000000000000ED
:1003100000000000000000000000000000000000DD
:1003200000000000000000000000000000000000CD
:1003300000000000000000000000000000000000BD
:1003400000000000000000000000000000000000AD
:10035000000000000000000000000000000000009D
:10036000000000000000000000000000000000008D
:10037000000000000000000000000000000000007D
:10038000000000000000000000000000000000006D
:10039000000000000000000000000000000000005D
:1003A000000000000000000000000000000000004D
:1003B000000000000000000000000000000000003D
:1003C000000000000000000000000000000000002D
:1003D000000000000000000000000000000000001D
:1003E000000000000000000000000000000000000D
:1003F00000000000000000000000000000000000FD
:00000001FF
ほぼ想定の結果が得られました。比較的うまくいっているようです。これからわかることは、01 (reset)の次はすべて00で、MCUSRレジスタから得られた情報はなさそう。
同期情報もしっかり記録されており、同期も機能していそうです。
事前検証はこれで、完了とします。つぎはいよいよ、AD変換でのデータ収集の実験に入っていきます。
参考サイト:
avrdude の使い方 (電子工作の実験室)
Arduinoのプログラムを吸い出す方法 (Lang-ship)